

Semantische Auszeichnungen automatisieren
Stellen Sie sich folgendes Szenario vor: Sie haben mit viel Mühe eine Webseite erstellt und bekannt gemacht, sodass sie endlich in den Google Suchergebnissen auf Seite eins erscheint. Der Suchende und ihre Webseite sind nur noch einen Mausklick entfernt. Allerdings steht Ihr Angebot zwischen den Angeboten mehrerer Wettbewerber. Wie können sie sich jetzt durchsetzen? Was könnte den Anstoß geben, dass der Suchende eher auf ihr Angebot klickt? Die Antwort lautet: Rich Snippets (englisch: ergiebige Schnipsel). Denn Suchergebnisse mit Rich Snippets wirken interessanter und können somit den Klickerfolg steigern.
Was sind Rich Snippets?
Als Snippets (englisch: Schnipsel) bezeichnet man die Zeilen, die unter dem Suchergebnis erscheinen. In der Regel ist dies der Text, den sie im Meta Element <description> ihrer Webseite angegeben haben. Wenn das Meta Element fehlt, wird die Suchmaschine aus anderen Elementen eine Kurzbeschreibung einsetzen. Abbildung 1 zeigt Snippets für den Suchbegriff „Carbonara“.
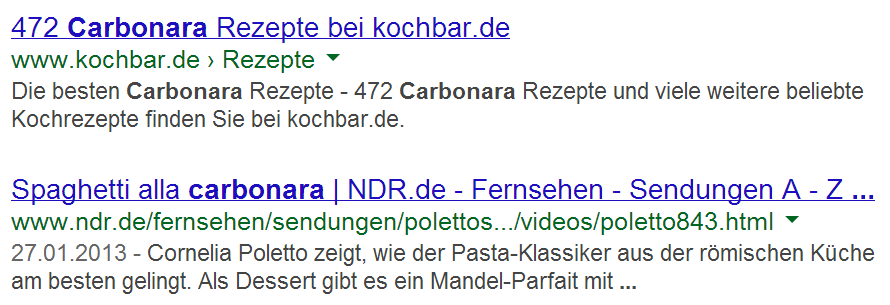 Quelle: screenshot google Abbildung 1 – Einige Suchergebnisse zu „Carbonara“
Quelle: screenshot google Abbildung 1 – Einige Suchergebnisse zu „Carbonara“
„Computer sind doof“ heißt ein Song der Band Spliff aus dem Jahr 1982. Auch 32 Jahre später hat sich dieser beklagenswerte Zustand der Informationstechnik nicht grundlegend verbessert. Deshalb fällt es einer Suchmaschine so schwer, selbst einen sinnvollen und attraktiven Beschreibungstext für ihre Webseite zu formulieren.
Genau hier setzen Rich Snippets an und führen die Idee des Beschreibungstextes aus dem Meta Element <description> einen Schritt weiter. Der Deal ist so einfach wie wirkungsvoll: Sie erklären der Suchmaschine was ihre Webseite bedeutet, die Suchmaschine revanchiert sich mit einer attraktiveren Beschreibung, eben einem Rich-Snippet:
 Quelle: screenshot google Abbildung 2 – Einige Suchergebnisse zu „Carbonara“ mit Rich Snippets
Quelle: screenshot google Abbildung 2 – Einige Suchergebnisse zu „Carbonara“ mit Rich Snippets
Die Snippets in Abbildung 1 zu verstehen ist ziemlich mühselig. Die Suchergebnisse in Abbildung 2 erscheinen viel verständlicher. Die Rich Snippets, also mit Bildern, Symbolen und nützlichen Informationen angereicherte Beschreibungen, erleichtern das intuitive Verständnis und heben wesentliche Kriterien hervor.
Ein Rezept, von 89 Personen überwiegend positiv bewertet, 15 Minuten Zubereitungszeit, das wäre doch einen Versuch wert? Und schon ist genau dieses „Carbonara“ Suchergebnis geklickt, obgleich die 472 Carbonara Rezepte aus Abbildung 1 in der Suchergebnisliste bei Google weiter oben stehen. Wir wollen es doch heute meist schnell und einfach. Und bis ich 472 Rezepte gelesen habe ist mein Besuch längst weg.
„Computer sind doof“ hat in diesem Beispiel aber noch eine zweite Dimension. Suchmaschinen beabsichtigen für den Suchenden die relevantesten Ergebnisse zu finden. Dazu müssen sie aber nicht nur die einzelnen Webseiten verstehen, sondern auch was der Suchende mit dem Suchbegriff meint. Haben sie als Kind mal Teekesselchen gespielt? Dann wissen sie, dass fast jedes Wort mehrere Bedeutungen hat. Die richtige Zuordnung von Ergebnissen zu Suchbegriffen wird dadurch erschwert.
Zum Glück können uns Rich Snippets die Orientierung erleichtern. Bekanntlich ist die Mustererkennung eine besondere Stärke des Menschen. Kann der Suchende intuitiv zwischen „Carbonara“ (der Song) und „Carbonara“ (das Rezept) unterscheiden, so wird er das relevantere Ergebnis klicken. Wenn sich die Seite mit Rich Snippets klar differenziert, wird sie mit mehr Klickerfolg belohnt werden.
Man könnte jetzt skeptisch argumentieren, dass ja auch Klicks verloren gehen, wenn Suchende schneller erkennen können, dass die Seite für sie uninteressant ist. Wer den Song sucht klickt nicht auf das Nudelrezept, sofern der Unterschied klar ist. Das stimmt natürlich. Aber mal ehrlich, was nützt ihnen der Klick eines Verirrten, der die Seite ohnehin in kürzester Zeit wieder verlassen wird? Wenn Sie den Erfolg ihres Webauftritts in Konversionen messen, statt in Besucherzahlen oder Seitenaufrufen, dann sind verirrte Besucher für sie ohnehin uninteressant. Deren Klicks bringen ihnen keinen Klickerfolg.
Wie erkläre ich der Suchmaschine, was meine Seite bedeutet?
Der Trick, mit dem ihre Webseiten für Suchmaschinen verständlicher werden, ist die sogenannte semantische Auszeichnung im HTML-Quelltext. Semantische Auszeichnung ist nicht gerade neu, wird aber bisher im deutschen Sprachraum erstaunlich wenig angewendet. Inzwischen konkurrieren mehrere Standards um die Gunst der Webseitenbetreiber. Die drei gängigsten Formate sind:
- Mikrodaten
- Mikroformate
- RDFa / Lite 1.1
Google empfiehlt ausdrücklich die Verwendung von Mikrodaten, unterstützt aber – ebenso wie Bing und Yahoo – auch die beiden anderen Formate. Die gute Nachricht für sie lautet also: Nutzen sie einfach, was für ihr Projekt am besten passt! Dies kann sich zum Beispiel daraus ergeben, welche Content-Typen für ihre Webseite am wichtigsten sind und wie gut sie jeweils von den drei Formaten unterstützt werden.
Die semantische Auszeichnung unterscheidet bestimmte Inhaltstypen und kennzeichnet die zugehörigen Elemente. Somit erhalten die Content Elemente einer Webseite unterschiedliche Bedeutungen zugewiesen, die von Computern erkannt und verarbeitet werden können. Betrachten wir als Beispiel das Mikrodaten Format für den Typ Rezept. Es enthält mehrere Elemente, mit denen einzelne Content Elemente zur inhaltlichen Beschreibung eines Rezeptes ausgezeichnet werden können:
|
Element |
Typ |
Bedeutung |
| cookingMethod | Text | Methode, z. B. kochen, braten, backen |
| cookTime | Dauer | Kochzeit im ISO 8601 Format |
| ingredients | Text | Eine Zutat für das Rezepts |
| nutrition | NutritionInformation | Typ mit Nährwertangaben zum Rezept |
| prepTime | Dauer | Vorbereitungszeit im ISO 8601 Format |
| recipeCategory | Text | Rezeptkategorie, z. B. Vorspeise, Dessert |
| recipeCuisine | Text | Die Herkunft des Gerichts, z. B. asiatisch, italienisch |
| recipeInstructions | Text | Ein Schritt bei der Zubereitung |
| recipeYield | Text | Menge auf die sich die Zutaten beziehen, also z. B. 6 Portionen |
| totalTime | Dauer | Gesamtdauer im ISO 8601 Format |
Semantischen Auszeichnungen werden im HTML-Quelltext der Webseite eingebettet. Sie erläutern den Suchmaschinen, was einzelne Content Elemente bedeuten. Bei der Darstellung der Webseite im Browser ändert sich nichts, denn diese Auszeichnungen bleiben für den Menschen unsichtbar.
Computer mögen zwar doof sein, aber die semantische Auszeichnung hilft ihnen auf die Sprünge. Mit der zusätzlichen Information können Suchmaschinen relevantere Ergebnisse finden. Wenn wir nach „Dessert italienisch“ suchen, findet die Suchmaschine vielleicht ein tolles Tiramisu Rezept.
Enthält die Seite ein ansprechendes Foto mit semantischer Auszeichnung in Google konformer Größe, so lässt uns das Rich-Snippet sicher schnell das Wasser im Munde zusammenlaufen. Wer diesen Effekt mit einem reinen Beschreibungstext übertrumpfen will, verdient wirklich unseren Respekt.
Ohne Fleiß kein Preis?
Google, die in Deutschland am weitesten verbreitete Suchmaschine, unterstützt Rich Snippets für
- Erfahrungsberichte
- Personen
- Produkte
- Unternehmen und Organisationen
- Rezepte
- Veranstaltungen
- Musik
- Videos
Da ist für viele Webseiten etwas dabei. Eine einzeln „von Hand“ erstellte Webseite mit Rich Snippets auszuzeichnen, ist keine große Herausforderung. Für sogenannte Marketing Landingpages könnte das also eine interessante Option sein. Allerdings sind Landingpages oft an zeitlich begrenzte Kampagnen gekoppelt. Außerdem zeigen meist nur wenige Links von fremden Webseiten auf eine Landingpage. Aus Sicht der Suchmaschinen werden sie dann als wenig relevant eingestuft. Die Chance auf die erste Seite zu kommen ist gering. Auf einer Suchergebnisseite die kaum jemand anschaut, können Rich Snippets aber auch keine Wunder bewirken.
Den größeren Effekt bringen Rich Snippets daher für bereits SEO optimierte Seiten der Corporate Website, zum Beispiel für Themen wie Produktinformationen, Kundenreferenzen oder Veranstaltungshinweise. Diese Seiten werden natürlich längst nicht mehr von Hand gebaut. Die meisten Unternehmen setzen Content Management Systeme (CMS) für die Redaktion und Ausspielung ihrer Webseiten ein. Die Frage nach den Möglichkeiten zur semantischen Auszeichnung richtet sich somit zuerst an die CMS Hersteller und deren Dienstleister. Wenn der Einsatz von Content Management Systemen das Ziel verfolgt, mit möglichst wenig Redaktionsaufwand möglichst viel Effekt zu erreichen, dann sollte dies auch für die semantische Auszeichnung gelten.
Was ich nicht weiß kann ich nicht weitersagen
An dieser Stelle könnte es schwierig werden. Die kritische Frage lautet: Wie „intelligent“ ist der Content in ihrem CMS organisiert? Tatsächlich gibt es da eine große Bandbreite zwischen den Systemen. Simplere Content Management Systeme verwalten Seiten-Templates mit Platzhaltern. Die Redakteure erzeugen mit dem Editor unstrukturierte „Content-Blobs“, also ein Gemenge aus Texten, Bildern, etc., die an den Platzhaltern ins Template eingesetzt werden. Da die Redakteure praktisch an jeder Stelle alles schreiben können, genießen sie maximale Flexibilität. Weil sich das CMS nicht weiter um die Inhalte kümmert, kennt es aber deren Bedeutung nicht. Hier gilt also: was ich nicht weiß, kann ich nicht weitersagen.
Mit der Anforderung nach einer automatisierten semantischen Auszeichnung sind derartige Systeme schnell überfordert. Unter Umständen haben die Redakteure zwar direkten Zugriff auf das HTML des Content-Blobs, aber semantische Auszeichnungen „von Hand hineinzufrickeln“ kann wirklich nur ein Notbehelf sein.
Möglicherweise gibt es aber ein spezielles Modul oder ihr Dienstleister bietet die Entwicklung eines Custom-Moduls für sie an? Dann stellt sich die Frage, was das ggf. kostet, was es wirklich kann und wie gut sich das Bedienkonzept in die tägliche Redaktionsarbeit einfügt. Beispielsweise gibt es für das weit verbreitete WordPress System mehrere Microdata Plugins, die von den Nutzern sehr kontrovers bewertet werden.
Strukturierter Content ist King
Moderne, für den Unternehmenseinsatz konzipierte Content Management Systeme setzten von vornherein auf strukturierten Content. Idealerweise können vom Web-Entwickler beliebige Content Objekte „wie Lego“ aus einzelnen Elementen zusammengebaut werden. Derartig strukturierte Content Objekte bieten eine Vielzahl von Vorteilen:
- Dieselbe Information existiert nur einmal und wird bei Bedarf an unterschiedlichen Stellen / von unterschiedlichen Devices (oder Apps) verwendet. Dies
- reduziert den Pflegeaufwand und
- garantiert die Konsistenz der Information.
- Unterschiedliche Varianten desselben Elements (z. B. lange und kurze Überschrift) lassen sich gemeinsam pflegen und je nach Bedarf verwenden.
- Einzelne Elemente können für Automatisierungsregeln ausgewertet werden, z. B. „die fünf aktuellsten Pressemeldungen anzeigen“ oder „Kochrezepte nach Zubereitungszeit sortieren“.
Je einfacher die Content Struktur auch noch nach dem go-live erweitert werden kann, ohne die Integrität des bereits gespeicherten Contents zu gefährden, desto zukunftssicherer ist das System.
Wenn sie sich bei der Systemauswahl für ein derartiges CMS entschieden haben, sind sie dem Ziel der automatisierten semantischen Auszeichnung bereits sehr nah. Wahrscheinlich gibt es bereits Content Objekte mit einer passenden Struktur, um die benötigten Elemente abzubilden. Ist das nicht der Fall, so wird die Struktur einfach entsprechend erweitert. Das CMS wurde vom Hersteller ja genau für diesen Fall ausgelegt, sie müssen also nicht vom „Pfad der Tugend“ abweichen.
Da die Redakteure bereits gewohnt sind, mit strukturierten Content Objekten zu arbeiten, wird sich die Erweiterung, sofern überhaupt nötig, nahtlos in das vorhandene Bedienkonzept einfügen.
Semantische Auszeichnungen automatisch einfügen
Strukturierter Content ist die Voraussetzung, um die semantische Auszeichnung ihrer Webseiten zu automatisieren. Die Erfassung der Informationen wurde im vorigen Absatz geklärt. Wie kommt die dazu passende semantische Auszeichnung in den HTML-Quelltext der Webseite?
Content Management Systeme, die mit strukturierten Content Objekten arbeiten, haben natürlich auch Standardverfahren wie die Inhalte dieser Objekte in eine Webseite einzubetten sind. Statt individuelle Templates für jeden Seitentyp einzusetzen, benutzt man gerne ein Mastertemplate (oder wenige Templates bei sehr stark unterschiedlichen Seitentypen), dass den grundlegenden Seitenaufbau beschreibt. Die unterschiedlichen Seiten werden hieraus abgeleitet, indem unterschiedliche Informationscontainer mit dem Template verknüpft werden.
Informationscontainer kümmern sich um die Beschaffung der Inhaltselemente aus den betreffenden Content-Objekten und schreiben sie auf die Seite. Es könnte also beispielsweise einen Container für Pressemeldungen und einen Container für Rezepte geben. Je nachdem, wo sich der Besucher in der Navigationsstruktur der Website befindet, wird dann eine Pressemeldung oder ein Rezept in den Seitenrahmen eingebettet.
Das Ganze wird von Transformationslogik gesteuert, die je nach Technologie in einer Beschreibungssprache wie XSLT beschrieben oder in einer Programmiersprache wie Java programmiert ist. Das Ziel ist immer, dass Web-Entwickler die Transformationslogik auf individuelle Projektanforderungen anpassen können. Auch dafür müssen sie also nicht vom „Pfad der Tugend“ abweichen.
Weil die Transformationslogik ohnehin auf einzelne Elemente der strukturierten Content Objekte zugreift, „kennt“ sie auch deren Bedeutung. Deshalb reichen hier meist ein paar kleine Erweiterungen an geeigneter Stelle. Schon schreibt die Transformationslogik nicht nur das Inhaltselement in den Quelltext der Seite, sondern umgibt es mit der zugehörigen semantischen Auszeichnung.
Fortan erfolgt die semantische Auszeichnung ohne weiteres Zutun der Redakteure, gesteuert durch die Transformationslogik und die strukturierten Inhalte. Die Suchmaschine erzeugt Rich-Snippets für alle Seiten mit entsprechenden Inhalten, ohne das die Redakteure darüber nachdenken müssten. Das ist ähnlich komfortabel, wie früher beim Zeitungsdruck. Da konnten sich die Redakteure voll auf die Inhalte konzentrieren, weil für die Darstellung ein Setzer zuständig war.
Expertenmeinungen
Für diejenigen unter Ihnen, die Mitglieder der geschlossenen Gruppe „Content Management Professionals“ im LinkedIn Netzwerk sind, möchte ich auf eine aktuelle Diskussion zum Thema hinweisen. Die Frage war, weshalb wir so wenig Rich Snippets in Suchergebnislisten finden.
Einen Beitrag, mit dem ich die Diskussion zusammenfasste, gebe ich für Sie hier in Deutsch wieder. Zum besseren Verständnis habe ich einige Zusätze, die sich aus dem Kontext der Diskussion ergeben, in eckigen Klammern angefügt:
Was ich aus dieser Diskussion mitnehme ist folgendes: Es gibt derzeit zwei Arten von [Web Content Management] Systemen: solche, die automatisierte semantische Auszeichnungen ermöglichen (und die technische Komplexität des HTML vor den Redakteuren verbergen, wie Adriaan [Bloem] ausführte) und solche, die eher im Weg stehen (weil sie entworfen wurden, um Content Blobs zu verarbeiten [was bedeutet: sie kennen keinen strukturierten Content und vermischen Content und Darstellung]).
Mir scheint, dass die zweite Art derzeit den Markt dominiert. Mark [Baker] hat darauf hingewiesen, warum wir von den Content Bearbeitern nicht erwarten dürfen, dass sie das HTML Tagging selbst korrekt umsetzen, und warum wir von den Suchmaschinen nicht erwarten dürfen, die Mehrdeutigkeiten der menschlichen Sprache zu verstehen. In der Kombination erklärt dies, weshalb wir so selten Rich Snippets in den Suchergebnislisten sehen.
Da ich selbst zur „altmodischen strukturiert-den-Content Fraktion“ gehöre, freue ich mich besonders über Adriaan’s praktische Erfahrung das “[automatisch erzeugte] Snippets für uns in manchen Fällen einen großen Wettbewerbsvorteil bedeuten“.
Praktische Tipps
Überlegen sie, wie groß ihr jährlicher Aufwand für SEO ist. Wenn ein Großteil davon verpufft, weil Wettbewerber ihnen die Interessenten mit Rich Snippets weglocken, dann sollten sie genau dort den Hebel ansetzen. Umgekehrt gilt: weshalb sich nicht selber einen Vorteil verschaffen?
Sie sind sich nicht sicher, was die Technologie ihres CMS hergibt? Fragen sie einfach den Hersteller oder ihren Dienstleister. Möglicherweise kostet es weniger als sie denken, ihre Webseiten für Suchende attraktiver zu machen.
Planen sie für 2014 ohnehin die Auswahl eines neuen CMS? Dann denken sie an die Vorteile von strukturiertem Content und nehmen sie automatisierte semantische Auszeichnungen in ihrem Anforderungskatalog auf.
Weiterführende Links
- Über Rich Snippets und strukturierte Daten (Google Webmaster Tools)
https://support.google.com/webmasters/answer/99170?hl=de - Präsentation von Olle Olson (W3C) bei der J.Boye Web & Intranet Konferenz 2012 in Aarhus http://aarhus12.jboye.com/wp-content/uploads/slides/jboye-aarhus12-how-recent-approaches-to-metadata-is-improving-the-web-by-olle-olsson.pdf
- Präsentation von Kavi Goel (Google) mit Implementierungstipps für Microdata (schema.org)
http://schemaorg.cloudapp.net/2011Workshop/sw1109_Implementation.pdf
Bildquellen
- carbonara_snippet: screenshot google
- carbonara_rich-snippet: screenshot google
- SEO Capsule: photodune - koolander




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
No Comment