
News aus Online-Marketing und E-Commerce

PIM-Anbieter: Nachhaltigkeit und soziale Gerechtigkeit im Überblick
Heutzutage wird nachhaltiges Engagement und soziale Gerechtigkeit auch von Unternehmen zunehmend eingefordert. Für einige sind diese Bestrebungen sogar Kriterien bei der Auswahl neuer Unternehmenssoftware. Daher war es uns ein Bedürfnis, bei unserem großen Marktüberblick der Marktüberblick der PIM-Anbieter auch danach zu fragen: Welche Maßnahmen treffen die Anbieter, um Ressourcen und Emissionen zu sparen? Haben sie …

Social Media in der B2B-Kommunikation
Die Ansprache von Neukund:innen, die interne Kommunikation oder zur Stärkung des Markennamens: Social Media Kanäle bieten eine Vielzahl an Funktionen für B2B-Unternehmen. Lange vorbei sind die Zeiten, in denen soziale Netzwerke nur für B2C-Marketing reserviert war. Genau aus diesem Grund ist es wichtig, die Entwicklungen und Trends der B2B-Kommunikation auf Social Media zu erforschen. Zum …

Der KI-Chatbot ChatGPT – Was die künstliche Intelligenz für das Marketing leisten kann
ChatGPT hat sich in den letzten zwei Jahren – seitdem der Chatbot für die Allgemeinheit frei zugänglich ist – einen Namen gemacht. Viele nutzen die KI im Alltag, ob beruflich oder privat. Mit neuen Funktionen wie der Bildgeneration, der Text-to-Video Erweiterung oder dem Team GPT hat OpenAI ihr Repertoire stetig erweitert und sich an die …

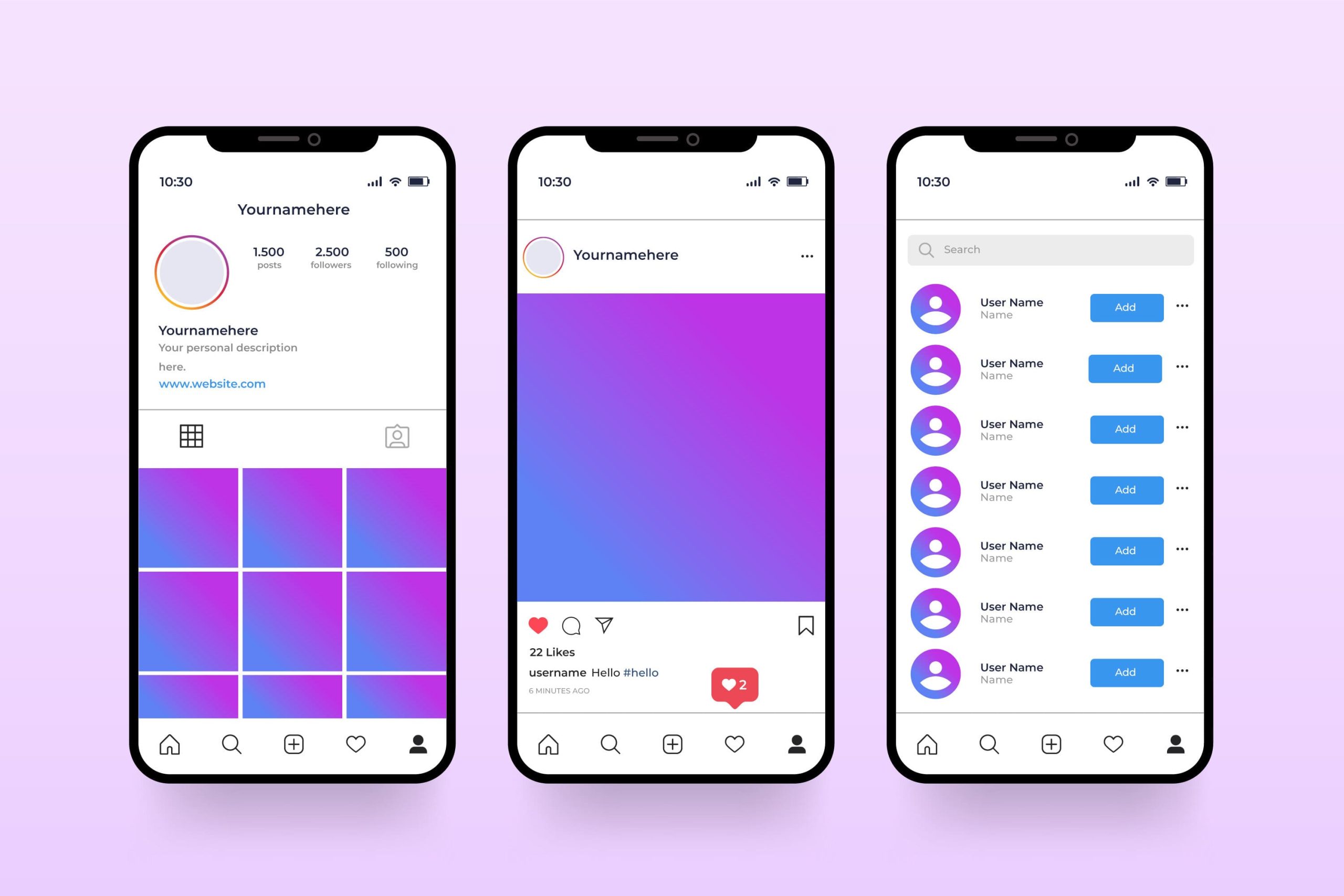
Marketing auf Instagram: Die Basics
30 Millionen Menschen in Deutschland nutzen Instagram – viele davon täglich. Die Social Media Plattform gehört zum Repertoire der erfolgreichen Marketing Strategie einfach dazu. Und das mittlerweile nicht nur beim B2C-Marketing, sondern auch bei B2B-Unternehmen. Von Engagement über Sponsored Posts bis hin zur Fan Base Interaktion: Das Marketing auf Instagram will gekonnt sein. Dieser Beitrag …

Rankingfaktor Page Experience – Was muss ich beachten?
Um in der Google-Suche hoch zu ranken, reicht es schon längst nicht mehr aus, das Haupt-Keyword so oft wie möglich im Text der Website unterzubringen. Eher im Gegenteil: Nützlich sollen die Inhalte vor allem sein und die Suchintention der User:innen erfüllen. Auch die Nutzerfreundlichkeit der Website ist essenziell. Diese wird in den Google Core Web …

Whitepaper: Headless CMS in der Praxis – Checkliste für den Headless Einsatz
Das Headless Konzept im Content Management gilt heute als die einfachste Möglichkeit, Inhalte auf verschiedenen Kanälen auszuspielen, ohne für jeden Kanal ein eigenes Content Management System nutzen zu müssen. Die Customer Experience lässt sich – so die mehrheitliche Meinung – deutlich verbessern, da Content ohne großen Aufwand passgenau für Kanal und Kunde/ Kundin aufbereitet werden …





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}