
robots.txt, Robots-Meta-Tag und andere Möglichkeiten
Suchmaschinen bzw. deren Crawler sind nicht unbedingt selektiv beim Indexieren einer Website: Sie beginnen meist auf der Startseite und folgen allen Links in die Tiefe. Dabei werden natürlich auch Inhalte erfasst, die für Suchmaschinen eigentlich nicht relevant sind. Solche Inhalte lassen sich aber sperren.
Wann Inhalte sperren?
Es gibt viele Fälle, in denen Teile einer Website oder sogar eine ganze Website für Suchmaschinen gesperrt werden sollten:
• Bei einem Relaunch wird der Inhalt der neuen Website oft unter einer Test-Domain (z. B. relaunch.meinewebsite.de) aufgebaut. Damit Google die neuen Inhalte nicht vorschnell abholt, sperrt man derartige Websites in der Regel für Suchmaschinen.
• Es kann sein, dass es auf einer Website bestimmte Inhalte gibt, die für Suchmaschinen nicht relevant sind (z.B. Traffic-Auswertungen). Falls diese nicht durch einen Login geschützt sind, sollten diese gesperrt werden.
• Auf manchen Website gibt es Inhalte in doppelter Form: als HTML-Datei und als PDF-Datei. In diesem Fall kann man dann die PDF-Dateien für Crawler sperren. Das Sperren von Inhalten hat konkrete Vorteile:
• Wenn Google viele irrelevante Inhalte abholt, bindet das „Crawler-Energie“. Ein Crawler kann pro Tag nur eine bestimmte Menge an Daten holen. Und auch der Platz im Index ist beschränkt. Wer den Index also mit irrelevanten Daten „flutet“, hat weniger Chancen darauf, seine wirklich wichtigen Inhalte zeitnah in den Index zu bekommen.
• Das Panda Update von Google hat gezeigt, dass die Suchmaschine durchaus alle Seiten einer Website bewertet. Wer dann viele irrelevante Inhalte hat, läuft Gefahr eine schlechte Gesamtbewertung und damit schlechte Rankings zu bekommen.
Auch Duplicate Content kann Probleme bescheren, wenn auch nicht in Form einer Abstrafung, wie es oft vermutet wird. Aber wenn z. B. alle Inhalte als HTML- und gleichzeitig als PDF-Datei angeboten werden, ist es möglich, dass die Suchmaschinen die PDF-Dateien in den Suchergebnissen auflisten. Das bringt dann oft eine schlechte Nutzer-Erfahrung. Schlägt sich aber auch in den Traffic-Zahlen nieder, denn viele Web-Analyse-Dienste erfassen einen PDF-Download nicht.
Das Sperren von Inhalten ist also in vielen Fällen sinnvoll. Aber welche Möglichkeiten hat man, Suchmaschinen und deren Crawler einzuschränken? Und was nutzt man wann?
Crawler einschränken
robots.txt
Seit 1994 existiert eine Möglichkeit, Inhalte über eine zentrale Datei zu sperren: die robots.txt. Diese Textdatei befindet sich im Wurzelverzeichnis einer Website und kann über die URL http://www.meinewebsite.de/robots.txt abgerufen werden. Das machen auch Suchmaschinen vor dem Besuch einer Website gemeinhin als Erstes. Auch wenn einige SEO-Tools das Fehlen einer robots.txt-Datei als Fehler anmerken, stimmt das sicherlich nicht: Wer keine Inhalte zu sperren hat, benötigt diese Datei auch nicht. In jedem Fall sollte Sie aber nur für das Sperren von Inhalten benutzt werden. Die Unsitte, diese Datei mit Suchbegriffen aufzufüllen, besteht zum Glück schon seit geraumer Zeit nicht mehr.
Es besteht über die Zeile „User-agent: …“ auch die Möglichkeit, verschiedenen Suchmaschinen unterschiedliche Sperrungen aufzugeben, sodass der Googlebot beispielsweise andere Inhalte sehen dürfte als der Crawler von Bing. In unserem Beispiel gelten die Sperrungen aber für alle Suchmaschinen („User-agent: *“).
Einige typische Einträge in der robots.txt-Datei lauten wie folgt:
• Alle Inhalte werden für alle Suchmaschinen gesperrt: User-agent: * Disallow: /
• Die Inhalte eines bestimmten Verzeichnisses werden gesperrt: User-agent: * Disallow: /info/
• Alle PDF-Dateien werden gesperrt: User-agent: * Disallow: /*.pdf
Wer sich für alle Möglichkeiten interessiert, sei auf die Wikipedia verwiesen, die eine gute Übersicht aller Direktiven nebst Beispielen bietet. Dort sieht man auch, dass es neben den Direktiven zum Sperren/Freigeben von Inhalten noch zwei weitere Angaben gibt, die grundsätzlich in dieser Datei platziert werden können:
• „Sitemap: URL“ – um die URL einer Sitemap-Datei an den Crawler zu übergeben
• „Crawl-delay: X“ – um den Crawler zu signalisieren, dass zwischen zwei Seitenabrufen X Sekunden gewartet werden soll.
Robots-Meta-Tags
Während die Datei robots.txt die Sperren/Freigaben zentral speichert, gibt es auch die Möglichkeit, in einzelne HTML-Dateien ein so genanntes Robots-Meta-Tag einzufügen, um so einem Crawler Hinweise zu geben. Für Crawler ist dabei vor allem das Attribut „noindex“ interessant, das wie folgt notiert wird:
<meta name=“robots“ content=“noindex“>
Wenn die Suchmaschine nach dem Herunterladen einer Seite das „noindex“-Attribut findet, signalisiert das der Suchmaschine, dass diese Seite nicht in den Index übernommen werden soll. Mit diesem Tag ist es also möglich, Sperrungen für ganz konkrete Seiten vorzunehmen, ohne dass diese in der robots.txt-Datei aufgeführt werden müssen.
In das Robots-Meta-Tag können übrigens auch deutlich mehr Angaben übernommen werden, die jeweils durch Kommata getrennt werden (teilweise werden diese nur von Google korrekt interpretiert):
•nofollow: Folge keinen Links auf dieser Seite
•noarchive: Lege keinen Cache-Eintrag für diese Seite an
•nosnippet: Zeige kein Snippet (Textausschnitt) in den Suchergebnissen an
•noodp: Übernimmt keine Beschreibung aus dem ODP-/DMOZ-Verzeichnis als Snippet
•notranslate: Biete keine Möglichkeit der Übersetzung für diese Seite an
•noimageindex: Übernimm keine Bilder aus dieser Seite in den Google-Bilder-Index
•unavailable_after: Nach dem genannten Datum wird die Seite nicht mehr in den Suchergebnissen angezeigt Angaben im HTTP-Header
Die Direktiven, die über das Robots-Meta-Tag übermittelt werden können, lassen sich übrigens auch im HTTP-Header übertragen, was aber wohl nur in den seltensten Fällen implementiert wird. Dann würde der HTTP-Server die Direktive in den HTTP-Header seiner Antwort aufnehmen, z.B. so:
HTTP/1.1 200 OK X-Robots-Tag: noindex, nofollow [Restlicher Header]robots.txt vs. Robots-Meta-Tag
Wenn man die robots.txt-Datei und das Robots-Meta-Tag gegenüberstellt, hat man zunächst das Gefühl, dass mit beiden Möglichkeiten dasselbe erreicht werden kann. Das stimmt zwar im Großen und Ganzen, aber nicht im Detail.
Die robots.txt-Datei verhindert, dass eine Seite vom Crawler einer Suchmaschine heruntergeladen wird. Das verhindert aber nicht, dass die Seite trotzdem in den Suchmaschinen-Index aufgenommen wird. Da der Crawler aber keine Informationen über die Seite liefern kann, sieht das Suchmaschinen-Ergebnis in der Regel „leer“ aus. Ein Beispiel findet sich in Abbildung 1: Die Seite http://www.techfacts.de/presse/relaunch ist in der robots.txt-Datei gesperrt, aber es gibt dafür trotzdem einen Eintrag im Google-Index.
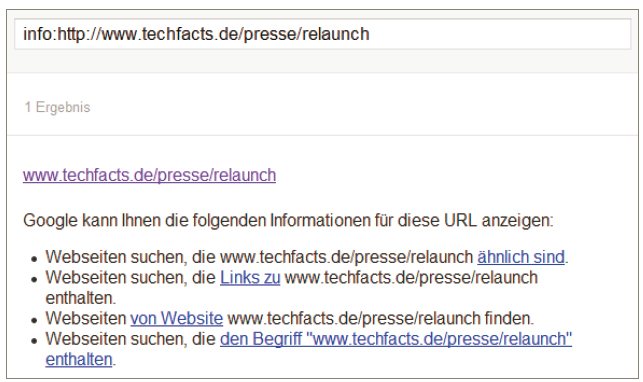 Abb.1: Eine per robots.txt gesperrte Seite im Google-Index
Abb.1: Eine per robots.txt gesperrte Seite im Google-Index
Das Robots-Meta-Tag hingegen erfordert, dass der Crawler die Seite zunächst herunterlädt, um dann dort das Tag zu finden. Dafür kann aber über das „Noindex“-Attribut verhindert werden, dass ein Eintrag im Google-Index angelegt wird.
Inhalte richtig sperren
Wer Inhalte konsequent sperren möchte, könnte also auf die Idee kommen, beide Methoden kombiniert zu benutzen. Das hat nur den klaren Nachteil, dass durch eine Sperrung in robots.txt der Crawler die Seite erst gar nicht herunterlädt, um dann dort das Robots-Meta-Tag zu finden. Wer also verhindern möchte, dass eine Seite irgendwie im Google-Index erscheint, darf folgerichtig die Inhalte nicht über die robots.txt-Datei sperren.
 Abb.2: Wie sperrt man Inhalte richtig?
Abb.2: Wie sperrt man Inhalte richtig?
Ein Beispiel dafür findet sich in Abbildung 2: Die URL http://www.bz-berlin.de/suche/Test befindet sich im Google-Index. Dabei sollte es diesen Eintrag eigentlich gar nicht geben:
• In der robots.txt-Datei steht „Disallow: /suche“
• Im Robots-Meta-Tag steht „nofollow, noindex“
Robots-Meta-Tag und robots.txt haben übrigens noch einen weiteren Unterschied: In robots.txt kann man Anweisungen nur für bestimmte Crawler einschränken. So könnte man eine Website für Google öffnen, für die russische Suchmaschine Yandex aber sperren. Die Granularität ist mit den Robots-Meta-Tags nicht möglich.

Schnelles Löschen von Inhalten
Es dauert manchmal nur Sekunden, um einen Inhalt in den Google-Index zu befördern, aber es
kann Monate dauern, bis der Eintrag wieder raus ist. Auch, wer einen Inhalt über die robots.txt oder das Robots-Meta-Tag sperrt, wird leere Einträge (wie in Abbildungen 1 und 2, also ohne Snippet) oft noch Monate lang im Index finden können. Meistens ist das kein Problem, aber manchmal eben doch – z.B., wenn es rechtliche Streitigkeiten gibt, in deren Folge bestimmte Inhalte aus dem Internet und damit auch aus Google entfernt werden mussten.
In diesen Fällen kann man die Google Webmaster-Tools nutzen, um ganz bestimmte URLs, ganze Verzeichnisse oder die Inhalte einer kompletten Subdomain aus dem Index zu tilgen („Website-Konfiguration > Crawler-Zugriff > URLs entfernen“, siehe Abbildung 3). Das funktioniert aber nur dann, wenn die zu löschenden Dateien auch für Suchmaschinen gesperrt sind (über robots.txt oder Robots-Meta-Tag). Die Löschungen werden in der Regel sehr schnell (innerhalb weniger Stunden) umgesetzt.
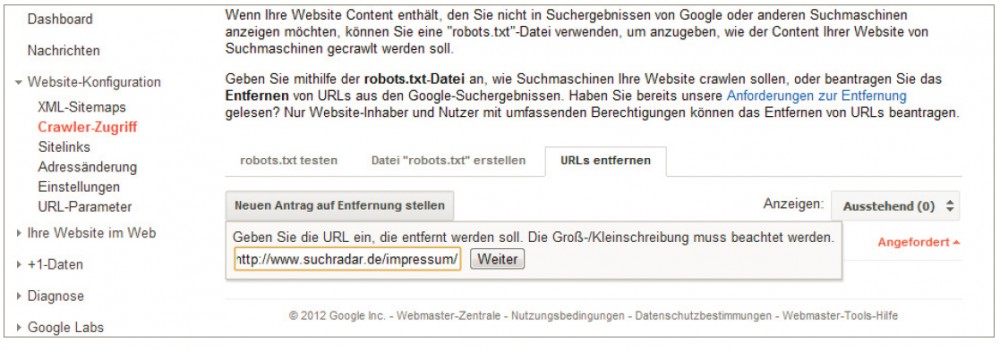 Abb.3: Schnelles Löschen von Inhalten über die Google Webmaster Tools
Abb.3: Schnelles Löschen von Inhalten über die Google Webmaster Tools
Weitere Möglichkeiten
Google bietet übrigens über seine Google Webmaster-Tools noch weitere interessante Möglichkeiten in Bezug auf das Sperren von Inhalten. So gibt es das Feature „Abruf wie durch Googlebot“, mit dem man eine Seite durch Google herunterladen lassen kann. Wenn die Seite gesperrt ist – wie in Abbildung 4 – wird das auch direkt angezeigt. Man kann so also prüfen, ob das Sperren bestimmter Seiten auch korrekt erkannt wird.
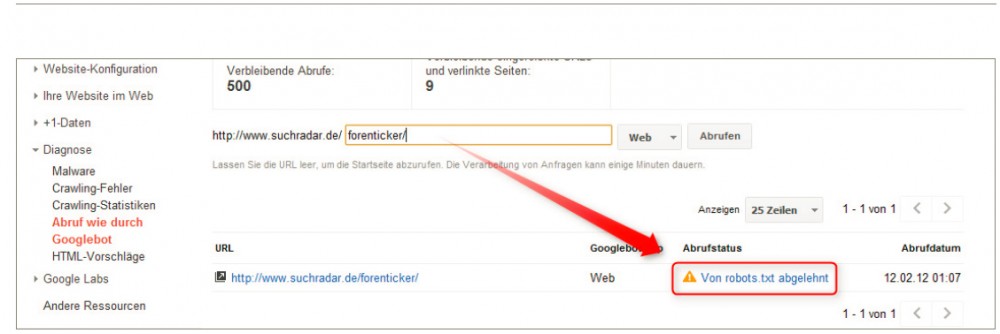 Abb.4: Prüfen, ob das Sperren bestimmter Seiten auch korrekt erkannt wurde
Abb.4: Prüfen, ob das Sperren bestimmter Seiten auch korrekt erkannt wurde
Auch gibt es in den Webmaster-Tools unter dem Punkt „Website-Konfiguration > Crawler-Zugriff“ die Möglichkeit, die Inhalte einer robots.txt-Datei im Original zu überprüfen oder sie temporär zu verändern und dann bestimmte URLs einzugeben. Google überprüft dann, welche der URLs durch welche Direktiven gesperrt werden.
Und wer beim Schreiben einer robots.txt-Datei Hilfe braucht, findet unter dem Punkt „Website-Konfiguration > Crawler-Zugriff > Datei robots.txt erste“ auch gleich ein Google-Tool, um Schritt für Schritt eine solche Datei zu erzeugen und im Anschluss hochzuladen.
Fazit
Das Sperren von Inhalten ist gar nicht so einfach. Je nachdem, welches Ziel man erreichen möchte, sollte man die robots.txt-Datei nutzen oder ein Robots-Meta-Tag in die eigenen Seiten einbauen. Und mithilfe der Google Webmaster-Tools lässt sich das auch noch sehr gezielt überprüfen, sodass es dabei keine ungewollten Schäden geben sollte.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
No Comment