

In diesem Artikel erfahren Sie, wie man Duplicate Content gezielt finden kann. Denn die Therapie kann bekanntermaßen erst nach der Diagnose beginnen.
Die üblichen Verdächtigen
Zunächst gibt es bei fast jeder Website „die üblichen Verdächtigen“, die man schnell und unkompliziert finden und überprüfen kann. An erster Stelle sind hier mit Sicherheit die Druckversionen zu nennen. Auch wenn es prinzipiell möglich ist, eine Druckfunktion über CSS und JavaScript zu realisieren, ist das in den seltensten Fällen auch so gelöst.
Wer z.B. die Seite http://www.bfs.de/de/kerntechnik/strommengen.html besucht, wird dort einen Link auf eine Druckversion finden. Falls die dort verlinkte Seite (in diesem Fall: http://www.bfs.de/de/kerntechnik/strommengen.html/printversion) eine andere URL hat, ist das ein sicheres Zeichen dafür, dass es für jede Seite eine separate URL für die Druckversion gibt – und dass es sich dabei um Duplicate Content handelt.
Nun muss man nur noch über das Google-Kommando „info:URL“ überprüfen, ob Google die URL der Druckversion kennt, also ob Google die Seite indexiert hat. Da das in dem konkreten Beispiel so ist, sollte man hier tätig werden.
Sub-Domains
Oftmals kommt es vor, dass eine Website nicht nur als www.domain.de, sondern z.B. auch als domain.de (ohne www.) oder auch als www2.domain.de indexiert wird. In der Regel wird eine Website dabei mehrfach mit identischem Inhalt erfasst, was durchaus zu Problemen führen kann.
Mit der Suchanfrage „site:domain.de -site:www.domain.de“ kann man gezielt nach derartigen Problemen suchen. Wenn man das z.B. für die Domain Augsburg.de macht, sieht man schnell, dass es sehr viele (oft legitime) Sub-Domains gibt. Man entdeckt aber auch z.B. die Sub-Domain www2.augsburg.de, die bei einer manuellen Überprüfung schnell als Dublette von www.augsburg.de erkannt wird.
Wer sich den Audi-Shop anschaut, entdeckt ein Problem, das Online-Shop oft haben: Die Website wird doppelt indexiert, und zwar als http://www.domain.de und als https://www.domain.de.
Mit der Suchanfrage „site:www.domain.de -inurl:http“ kann man schnell prüfen, ob Google auch Seiten erfasst hat, die verschlüsselt übertragen werden. Wer das also für Audi mit der Suchanfrage „site:shop.audi.de -inurl:http“ prüft, sieht, dass der Shop auch verschlüsselt erfasst wurde.
Störende Parameter
Oftmals finden sich auch störende Parameter in der URL. Ob Session-IDs oder Tracking-Parameter: Schnell entsteht hier doppelter Content. Zum Glück kann man diese Parameter sehr leicht über entsprechende Google-Anfragen finden – wenn man denn weiß, wie diese Parameter heißen.
Über die folgenden Abfragen kann man einige der üblichen Verdächtigen überprüfen: inurl:utm_source site:domain.de inurl:jsessionid site:domain.de inurl:sid site:domain.de inurl:PHPSESSID site:domain.de > …Phrasen-Test
Wer auf der Suche nach Duplicate Content ist, kann über diese Suchanfragen aber nur die Standardfälle überprüfen. Die effektivste Methode, um fast ausnahmslos Duplicate Content aufzudecken, besteht allerdings daran, einfach nach einer Phrase aus dem eigenen Content zu suchen.
Wer also z.B. aus einer Seite eine Phrase wie „Für die heute betriebenen Kernkraftwerke wurde mit dieser Novellierung gesetzlich normiert“ kopiert und diese bei Google sucht (inklusive der Anführungsstriche), erhält dabei alle Webseiten, die Google kennt und denen genau diese Phrase vorkommt. In der Regel wird man bei Google auf der ersten Suchergebnisseite noch auf den Link „die Suche unter Einbeziehung der übersprungenen Ergebnisse wiederholen“ klicken müssen, um auch wirklich alle Seiten angezeigt zu bekommen.
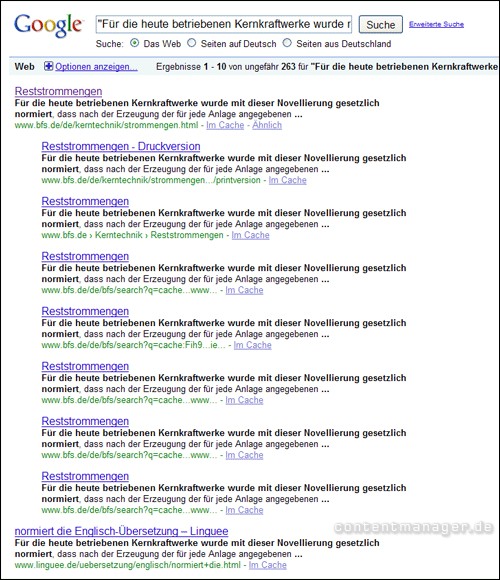 Abbildung 1: Phrasen-Test liefert Duplicate Content
Abbildung 1: Phrasen-Test liefert Duplicate Content
Wie man in Abbildung 1 sieht, erhält man dann oftmals viele URLs, auf denen derselbe Content zu finden ist. Im konkreten Beispiel wären das z.B.
1. Die Originalseite: www.bfs.de/de/kerntechnik/strommengen.html
2. Die Druckversion: www.bfs.de/de/kerntechnik/strommengen.html/printversion
3. Einige Cache-Versionen (wahrscheinlich vom CMS erzeugt) z.B.: www.bfs.de/de/bfs/search?q=cache:Fih9_sq83CgJ:www.bfs.de/kerntechnik/strommengen.html
+strommengen&ie=latin1&oe=ISO-8859-1
4. Seiten, die Teile des Contents indexiert haben, z.B.: www.linguee.de/uebersetzung/deutsch/npp.html
Es gilt danach also zunächst den internen Duplicate Content in den Griff zu bekommen und z.B. über ein Canonical-Tag identische Seiten zusammenzuziehen. Aber auch der externe Duplicate Content, also Content auf anderen Domains, muss in Angriff genommen werden.
Leider hat man hier natürlich nicht immer volle Kontrolle über fremde Websites. Insbesondere wenn die eigene Website einfach komplett kopiert wird und der Besitzer der Domain sich in Asien, Afrika oder Südamerika befindet, ist man hier schnell am Ende der Möglichkeiten.
Aber nicht immer muss es so sein, dass der eigene Content unkontrolliert den Weg auf andere Websites gefunden hat: Insbesondere bei Online-Shops ist Duplicate Content ein großes Problem. So kommt es natürlich oft vor, dass ein Online-Shop nur die Standard-Produktbeschreibungen des Händlers übernimmt.
Aber auch wer sich eigene Texte ausdenkt, kann hier Probleme heraufbeschwören, wenn diese Texte an Plattformen wie Yatego oder Amazon weitergegeben werden. Dann kann es schnell passieren, dass diese mit dem kopierten Content in den Suchergebnissen erscheinen und der Online-Shop, der über den „echten“ Content verfügt, in den Ergebnissen nach unten durchgereicht wird. Prinzipiell müsste jeder Online-Shop jeden Text zweimal schreiben: Einmal für die eigene Website und einmal für die Syndizierung an Partner und Plattformen.
In Abbildung 2 sieht man, wie oft eine Phrase aus der Produktbeschreibung eines Rasenmähers bei Google gefunden wird. Diesen Text findet man so auf ca. 20 anderen Websites, was die Chancen senkt, dass die eigene Website dafür zu finden ist.
 Abbildung 2: Identische Produktbeschreibungen
Abbildung 2: Identische Produktbeschreibungen
Software
Es gibt natürlich auch viele Software-Lösungen, mit denen man nach doppelten Inhalten fahnden kann. Während viele Lösungen wie Copyscape/Copysentry kostenpflichtig sind, kann man auch eine Software aus Deutschland nutzen: UN.CO.VER . Diese Software eignet sich hervorragend, um einzelne Textabschnitte, eine bestimmte Seite oder sogar eine komplette Website seitenweise zu überprüfen.
Interessanterweise findet diese Software auch Near Duplicate Content, also Inhalte, die nicht absolut identisch sind, aber gewisse Überschneidungen haben. Der Grad der Überschneidung wird als Prozentzahl angezeigt, sodass man abschätzen kann, wie „unique“ der eigene Content eigentlich ist.
Fazit
Duplicate Content ist nach wie vor ein Problem. Zur Begrenzung des Problems gibt es viele Möglichkeiten, z.B. Canonical-Tags oder die neue Google-Funktion zur Parameterbehandlung. Aber zunächst muss Duplicate Content eben gefunden werden, was nicht immer auf den ersten Blick gelingt. Die Taktiken in diesem Artikel helfen Ihnen hoffentlich, gezielte doppelte Inhalte zu finden.
Bildquellen
- view-computer-monitor-display (2): Freepik




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
[…] Duplicate Content suchen und finden […]