
Neue mediale Herausforderungen verdeutlichen einen zentralen Erfolgsfaktor semantischer Software: Das kontextspezifische Sprachverständnis. Das Thema öffnet Chancen für semantische Verlagsprodukte.
Seit Wikileaks ist klar: Das Informationszeitalter bietet enorme Möglichkeiten um Missstände zu entlarven (sog. Whistleblowing ). Gleichzeitig hält es aber auch eine neuartige Bedrohung parat – die mediale „Freakwave“. Die Monsterwelle . Das Original bringt auf hoher See größte Schiffe in Seenot. Das mediale Gegenstück macht ebenfalls keinen Halt vor den ganz Großen: Weder vor wirtschaftlichen Global-Playern noch vor Supermächten wie den USA!
Keimzelle des Phänomens ist das Social-Web: Hier kann sich hoch explosive Information rasend schnell verbreiten – besonders dann, wenn sie einem unerwünschten Leck entweicht, einem „Leak“. Das allein reicht jedoch nicht aus, um von einer medialen „Freakwave“ zu sprechen. Zu ihr kommt es erst, wenn sich auf der Social-Web-Woge eine zweite Welle aufbaut: Es ist die vom permanenten Quotendruck getriebene Berichterstattung der klassischen Medien. Die unkalkulierbare Wechselwirkung beider Wellen kann eine einzigartige mediale Gewalt entwickeln.
 Grafik 1: „Freakwaves“ auf See und in den Medien
Grafik 1: „Freakwaves“ auf See und in den Medien
Quelle: Segelclub Prinzensteg
„Freakwaves“ entstehen durch die Wechselwirkung von mindestens zwei Wellen. In den Medien entspringt die erste Welle dem anarchischen Teil des Social-Webs. Sind die Inhalte brisant, dann besitzen sie für die klassischen Medien automatisch Quotenrelevanz. Bei Informationen von Whistleblowern ist dies häufig der Fall. Damit steigt die Gefahr einer zweiten, auf dem Wettbewerb professioneller Newsprovider basierenden, sich rasant aufpeitschenden Kommunikationswelle. Die unvorhersehbare Wechselwirkung beider Wellen kann eine Energie erzeugen, die jede der beiden Wellen allein kaum erzielen könnte. Ein Nebeneffekt: Die klassischen Medien stehen durch die „Wellenteilung“ vor der Herausforderung , ihre journalistische Rolle im Hinblick auf Scoops neu zu definieren.
Mitunter ist die erste Doppelwelle nur der Anfang einer Kettenreaktion: Wehrt sich der Betroffene, kann es zu einem Phänomen kommen, das auf See “ die drei Schwestern“ genannt wird. Es ist das Aufeinanderfolgen mehrerer Superwellen. Das Wikileaks-Beispiel hat unmissverständlich verdeutlicht, wie unberechenbar die Reaktion sein kann, wenn man versucht, die Basiswelle, also das Social-Web zu kontrollieren: Im Zweifel kommt es dann zur Mobilisierung der digitalen “ Wut-User „. Die Konsequenz: Eskalation anstatt Kontrolle.
| erste Welle | zweite Welle | |
| Publisher | Social Web | professionelle Newsprovider |
| Kanäle | Internet | Fernsehen, Radio, Print, Internet |
| Struktur | chaotisch; besitzt hohe Zersplitterung (Long-Tail) | professionelle Organisation und hohe Reichweite |
| Thema | geheime und/oder brisante Information mit anschließender Diskussion | berichtet über das Phänomen der ersten Welle, deren Inhalte und den Versuch der Betroffenen sie zu bekämpfen |
| Sprache | gesamtes Spektrum von (verschlüsselten) Nischen-Sprachen bis hin zu Mainstream | journalistische Sprache ist i.d.R. linguistisch regelkonform |
| Treiber | Überzeugung, Risikobereitschaft, Selbstverwirklichung, Wahrheitssuche; potenziell: Denunziation | journalistische Informationsversorgung, Geschäft, Quote, Wettbewerb |
| Kodex | tabulose Rebellion; wird z.T. als „Robin-Hood“-Mentalität empfunden und auch so dargestellt | besitzt viele empirisch gewachsene Tabus; journalistische „Ehre“; wirtschaftliche Abhängigkeiten |
| Speed | hohe Geschwindigkeit gerade bei besonders brisanten Themen | verglichen mit erster Welle eher ein Spätzünder |
| Recht | nutzt Länder mit maximaler Pressefreiheit (z.B. Schweden) | ist meist schärferen regionalen Presse- und Strafgesetzen unterworfen |
| Kontrolle | anarchisch, unberechenbar und daher kaum angreifbar und regulierbar; Gegenwehr u.a. Gefahr durch Hackerangriffe | ist „unschuldig“ an erster Welle, kann deshalb diesbezüglich „frei“ berichten |
| Gewalt | ermöglicht und forciert neue Dimension des primären, investigativen „Sprengstoff-Journalismus“ | enorme Wucht durch umfassende, anhaltende und z.T. reißerische Sekundärberichterstattung |
| Monitoring | aufgrund von Long-Tail und Nischen-Formaten extrem umfassend und komplex; permanente Veränderung; z.T. eigene anarchische Sprachwelten | zwar umfangreich, aber dennoch vergleichsweise einfach, da leicht zu lokalisieren; sprachliche Regeln werden weitgehend beachtet |
Grafik 2: „Freakwave“ durch Wechselwirkung von Social-Web und klassischen Medien
Ohne Web 2.0 wäre eine Freakwave wie Wikileaks schon aus rechtlichen Gründen kaum vorstellbar. Klassische Medien können zudem aufgrund faktischer Zwänge viel besser im Zaum gehalten werden. Das Web 2.0 durchbricht jedoch rechtliche Grenzen ebenso wie empirisch gewachsene (journalistische) Tabus und setzt professionelle Newsprovider sogar unter Zugzwang, sich ins Kielwasser des Leak-Journalismus zu begeben.
Durch Whistleblower-Portale wird der Prozess von investigativer Erstveröffentlichung und intensiver Sekundärberichterstattung irreversibel durcheinander gewirbelt und völlig neu definiert. Die Verlagerung von hoch brisanten Scoops ins anarchische Web 2.0 macht eine (rechtzeitige) inhaltliche Beurteilung der sachlichen Richtigkeit von „Leaks“ zugleich immer schwieriger.
Veränderte Medienwelt
Mediale Freakwaves sind bisher zwar selten vorgekommen. Die Situation könnte sich aber rasant ändern, denn es ist mittlerweile ein Wettbewerb um die Veröffentlichung brisanter Informationen innerhalb des Social-Web sowie zwischen Social-Web und klassischen Medien als auch unter professionellen Newsprovidern entstanden. Zudem ist zu befürchten, dass durch weitere Wikileaks-Kopien die gesunde Hemmschwelle zur Veröffentlichung brisanter Information im Social Web insgesamt weiter sinkt.
Jede Community wird so zum potenziellen „Mini-Leaks“. Das soziale Web könnte damit nicht nur zum El-Dorado für verantwortungsvolle Whistleblower, sondern auch für verantwortungslose Denunzianten werden – und wie hält man in Zukunft beides auseinander? Die Pressefreiheit gewinnt jedenfalls nicht nur durch diese Entwicklung – sie ist gleichzeitig der potenzielle Verlierer! Erst Recht dann, wenn Hacker zur Verteidigung des „Leak-Journalismus“ zum Cyber-War aufrufen!
In Anbetracht solcher Umstände wird ein Punkt immer klarer: Es ist die allgemeine Notwendigkeit, das Geschehen im Web 2.0 permanent zu beobachten, systematisch zu erfassen und auszuwerten, also Monitoring zu betreiben – auf Seiten von Unternehmen als auch auf Seiten von Organisationen und dem Staat.
Aber wie? Der Ozean des Web 2.0 ist riesig!
Vor der Antwortsuche, sollte man zunächst folgendes verinnerlichen: Wikileaks als solches ist nicht die Revolution als die es oft dargestellt wird! Das Beispiel war und ist vielmehr die absehbare und damit konsequente Folge einer seit Jahren andauernden Entwicklung die noch längst nicht abgeschlossen ist: Es geht um den Einfluss des Web 2.0 auf das reale Leben! Wikileaks markiert folglich nur die aktuelle Spitze eines Eisbergs – eines gigantischen Gletscher-Abbruchs , der unkontrolliert über das offene Meer treibt, der nicht nur die helle, sondern auch die dunkle Seite des Social Web symbolisiert.
Speziell im Hinblick auf die Nutzung von „Leaks“ werden beide Seiten dieses Bergs durch einen medialen Teufelskreis gespeist:
„The more widely you distribute information, the more likely it is to leak. If you disseminate it very widely by electronic means, it’s almost certain to leak.“ ( bclocalnews)
Die Krux: Jede „Freakwave“ lässt durch die zuvor skizzierte Logik die Gefahr weiterer Riesenwellen steigen! Potenzielle „Leaks“ aufzuspüren und zu „stopfen“ könnte vor diesem Hintergrund alsbald eine der wichtigsten Aufgaben für Unternehmen, Organisationen und Staaten sein. Gleiches gilt damit auch für das Monitoring von internen und externen Kommunikationsprozessen.
Der Einsatz von Menschen ist beim Monitoring fraglos der beste Weg – dieser Weg stößt aber schon heute an seine Grenzen. Und wie wird es sein, wenn noch viel mehr Monitoring betrieben werden muss? Nicht zuletzt aufgrund von wachsendem Kosten- und Zeitdruck steigt vielerorts die Hoffnung auf eine neue Generation intelligenter Software.
Die zunehmende Dringlichkeit bildet die Überleitung zum eigentlichen Thema dieses Beitrags: Der langjährige Status des semantischen „nice-to-have“ weicht immer mehr der Einsicht eines „must-have“! Es wird damit auch immer zwingender, die Erfolgsfaktoren semantischer Technologie genauer unter die Lupe zu nehmen! Auf Basis einer entsprechenden Analyse gilt es, neue Wege prüfen, um anschließend bessere Lösungen zu entwickeln. Solche, die nicht nur für das Semantic-Web, sondern auch für interne als auch externe Kommunikationsprozesse von Unternehmen geeignet sind, z.B.:
- Intern bei der Analyse von ein- und ausgehenden Informationen (ähnlich der e-Discovery ) sowie der Suche (Enterprise-Search) usw.
- Extern beim Monitoring des Social Web (z.B. semantische Crawler ) als auch im Bereich der Kundenkommunikation (z.B. Anfrage- und Beschwerdemanagement) usw.
Semantische Bojen messen den Wellengang im Web 2.0
Zunächst zum bereits angerissenen Thema „Social-Media-Monitoring“: Um den Wellengang im extrem zersplitterten Long-Tail des Social-Web möglichst automatisiert messen zu können, wird seit längerem an der Entwicklung spezieller semantischer Softwarelösungen gearbeitet. Sie sollen Communities und Blogs ununterbrochen scannen und Alarm schlagen, falls sich etwas Verdächtiges tut. Allerdings geht es dabei bislang weniger um „Leak-Detection“, sondern vor allem um die Identifikation kritischer Produktbewertungen:
- Automobilhersteller wollen wissen, ob ihre Fahrzeuge gut abschneiden
- Pharma-Unternehmen interessieren sich für Nebenwirkungen von Medikamenten
- Geheimdienste suchen sicherheitsrelevante Äußerungen aller Art
- etc.
Egal ob für „Leak-Detection“ oder sonstiges Webmonitoring: Um entsprechende Informationen korrekt zu klassifizieren reichen rein statistische Methoden ebenso wenig aus wie eine Keyword-Search! Man muss den Inhalt von Texten ähnlich wie ein Mensch verstehen und deuten können, wenn man valide Schlüsse ziehen will!
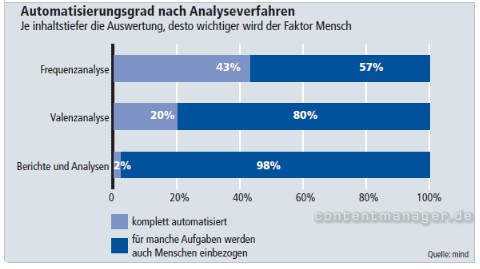 Grafik 3: Automatisches Monitoring
Grafik 3: Automatisches Monitoring
Quelle: Whitepaper Social-Media-Monitoring
Schon heute wird sowohl auf Basis von Keywords als auch mittels semantischer Technologie Social-Media-Monitoring betrieben. Aber je tiefer das Verständnis sein muss, desto wichtiger wird dabei der Mensch. Semantische Technologien stehen aber auch noch am Anfang. Sie besitzen viel Verbesserungspotenzial – dieses gilt es zu finden und in Lösungskonzepte umzuwandeln!
Speziell zur Interpretation des Web 2.0 braucht semantische Software mehr als bloß ein generelles Grundwissen ( vgl. dazu ausführlich Teil 2 ): Benötigt wird z.T. hoch spezielle Zusatzinformationen, um einen Text nicht nur „irgendwie“, sondern kontextspezifisch sinnvoll zu interpretieren. Nur wenn Grund- und Zusatzwissen vorhanden sind, kann auf Basis einer hinreichend genauen inhaltlichen Interpretation eine sinnvolle automatisierte Klassifikation und Zuordnung bzw. ein Alert erfolgen:
- Wo wird gerade im Social Web über meine Produkte geredet (Ortung)?
- Wie werden meine Produkte beurteilt (Bewertung)?
- Wo muss man aufgrund kritischer Entwicklung handeln (Maßnahmen)?
- Wo könnten sich gar „Freakwaves“ aufbauen (Gefahr)?
Der babylonische Ozean der Sprache
Die Entwicklung einer semantischen Lösung für Social-Media-Monitoring ist jedoch eine extrem harte Nuss, denn das Social-Web beinhaltet den wohl komplexesten Sprachcocktail den es gibt. Foren und Communities sind das Paradies für alle Arten sich permanent ändernder Sprachdimensionen z.B.:
- Lautsprache („2Fast4You“)
- Dialekt („i mog di“)
- Abkürzungen (“ 2F4Y „)
- Jugendsprache („fett“, „porno“)
- Neologismen (“ Niveau-Limbo „, “ brontal „)
- Migration (“ yalla / isch „)
- Grammatik („bring mich mal die Zeitung“)
- etc.
Diese bei weitem nicht abschließende Aufzählung verdeutlicht, wie schnell statistische Methoden an Ihre Grenzen stoßen! Die Zersplitterung der Sprache über den Long-Tail ist so gigantisch wie in der realen Wirklichkeit. Damit entsteht das von Chris Anderson skizzierte erweiterte Spannungsverhältnis von Signal und Rauschen auch im Hinblick auf Sprache.
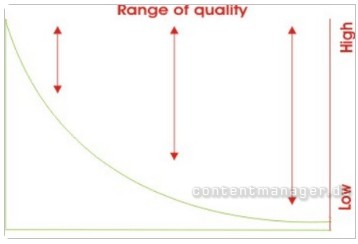 Grafik 4: Signal und Rauschen im Long Tail
Grafik 4: Signal und Rauschen im Long Tail
Quelle: longtail.typepad.com
Der Long-Tail verändert nach Chris Anderson in nahezu allen Bereichen das Verhältnis von Signal und Rauschen. Auch bei der Sprache. Zufall oder nicht: Aus linguistischer Forschung resultierte einst das Zipf‘sche Gesetz typischer Wortverteilung. Im Long-Tail verliert es allerdings an Aussagekraft: Je weiter der Long-Tail reicht, desto mehr sprachliche Nischen entstehen im Internet – die objektive Sprachqualität sinkt damit. Genau dieser Umstand ist allerdings aus Sicht der „eingeweihten Nischenuser“ ein subjektives Qualitätsmerkmal, weil diese mitunter eine Art “ Geheimsprache “ nutzen, die von Außenstehenden gar nicht verstanden werden soll!
Die unzähligen Sprachebenen und ungeschriebenen Regeln des Social-Webs sind in keinem Thesaurus oder irgendeiner Datenbank zu finden. Sie können bislang nur bedingt linguistisch aufgebarbeitet werden. Das ist allerdings kein spezifischer Nachteil von semantischer Software: Menschen tun sich mit dem Verständnis dieser anarchischen Sprachwelten ebenfalls schwer, falls sie nicht zu den „Native-Speakern“ einer anarchischen, nicht dokumentierten Sprache gehören!
Die Deutungsschwierigkeiten bei Social-Media beginnen damit allerdings erst! Die eigentlichen Inhalte sind nämlich im Hinblick auf die fachliche Ebene in vielen Fällen hoch speziell. Ein Beispiel aus dem Automobilbereich verdeutlicht exemplarisch die zu bewältigende Herausforderung in fachlicher Hinsicht:
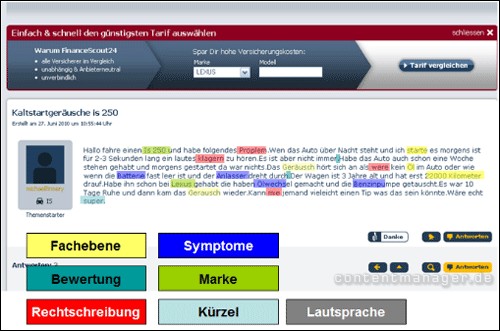 Grafik 5: Beispiel aus dem Automobilbereich
Grafik 5: Beispiel aus dem Automobilbereich
Quelle: Motortalk
Zum Scannen von Inhalten z.B. einer Automobil-Community benötigt eine semantische Software nicht nur ein sprachliches Grundwissen, vielmehr benötigt sie Fachkenntnisse über Automarken und Fahrzeugtypen, Fahrzeugteile, typische Redewendungen und Abkürzungen etc. Was ist ein „is 250“? Was ist ein „Ölwechsel“? Sie muss aber auch ahnen: Was könnte ein „proplem“ sein, was ein „Gerausch“ und was ein „klagern“? Es ist daher im jeweiligen Kontext zu prüfen: Ist „klagern“ ein falsch geschriebenes „Klackern“, ein unbekannter Fachbegriff oder ein in dieser Community entstandener (fachlicher) Neologismus? Mitunter fehlen auch Worte wie „geben“ im letzten Satz. Auch hier spielt der Kontext eine wichtige Rolle, denn man kann einen Satz nur ergänzen, wenn man zuvor kontextspezifische Kommunikationsziele erkennen und zuordnen kann.
Zusammengefasst kommt es damit zu einer mehrstufigen semantischen Kaskade als Basis der inhaltlichen Interpretation, der grob skizziert so aussieht:
- Kontextspezifische Kommunikationsziele, z.B.
- mitteilen
- überzeugen
- bewerten
- Hilfe bekommen
- Kontextspezifisches Spezialwissen, z.B.
- Fachbegriffe inkl. Synonyme (Ölwechsel, Kolbenfresser etc.)
- markenspezifische Information (Hersteller, Produkte etc.)
- Abkürzungen, Lautsprache, Neologismen
- Bewertungsdimensionen (u.a. Emoticons)
- Rechtschreibung
- spezielle linguistische Zusammenhänge und Regeln
- Grundwissen u.a.
- allgemeine Abkürzungen
- Grammatik
- Grundwörterbuch inkl. Rechtschreibung und Synonyme
- allgemeine linguistische Zusammenhänge und Regeln
Wichtig ist, dass innerhalb einer solchen Kaskade zunächst mögliche Kommunikationsziele und darauf basierend der fachliche und damit kontextspezifische Sinn interpretiert wird, bevor das allgemeine Grundwissen das Gleiche versucht: Ein „Käfer“ oder eine „Ente“ ist deshalb im Zusammenhang mit Automobilenportalen primär als Autotyp zu interpretieren (= VW 1200 – 1600 bzw. Citroen 2 CV ) und gerade nicht als Insekt bzw. Wasservogel. Für eine semantische Software eine durchaus komplexe Herausforderung!
Je nach Thema ist das Fachvokabular zudem sehr unterschiedlich! In der Medizin braucht man ein anderes Fachwörterbuch wie in der Juristerei, der Chemie oder der Betriebswirtschaft etc. Derartiges Fachwissen muss daher bei der semantischen Interpretation flexibel hinzugezogen bzw. hierarchisch geregelt werden können.
Es muss also definierbar sein:
- Welcher Kontext mit welchen Kommunikationszielen könnte bestehen?
- Welche Wörterbücher kommen beim konkreten Kontext in Betracht?
- Welches Verhältnis besteht zwischen konkurrierenden (Fach-)Wörterbüchern, Ontologien und Taxonomien im Rahmen des Kontext?
Die passende „Laufzeitkalibrierung“ eines semantischen Systems ist deshalb ebenso wichtig wie dessen Versorgung mit einer Vielzahl von fachlichen Inhalten.
Manuelle vs. automatische Annotation
Nun könnte man vermuten, dass das künftige Semantic-Web eine derartige Kaskade aufgrund kontextspezifischer Annotationen im RDF-Format weitgehend überflüssig macht. Im Semantic Web benötigt man sie nicht, da alle entsprechenden Interpretationsfragen anhand von Metadaten und deren Verlinkung „mitgeliefert“ werden. Semantische Community-Lösungen wie Kiwi werden auch künftig bei der semantischen „Aufladung“ von Social-Media-Inhalten eine große Hilfe sein. Aber trotz solcher Tools besteht ein großer Haken:
Wo kommen die zur korrekten Interpretation erforderlichen Metadaten her?
Leider ist die Annahme kaum realistisch, dass die Mehrzahl von Usern des Web 2.0 von solchen semantischen Werkzeugen Gebrauch macht, wenn die gleichen User nicht einmal einfachste Rechtschreibregeln beachten. Akkurate Annotation führt zu deutlichen Zusatzaufwänden. Den meisten Usern werden sie vermutlich zu hoch sein. Und selbst wenn nicht: Falls Annotationen fehlerhaft durchgeführt werden, dann sind diese wertlos oder noch schlimmer – sie werden zu einer Quelle zusätzlicher Konfusion!
Das Internet der nächsten Generation droht deshalb zu einem „Freak-Web“ zu werden, wenn es ausschließlich vom manuellen semantischen Input der Autoren abhängt. Hilfe kann deshalb wohl nur eine (semi-) automatische Annotation von x-beliebigen Inhalten liefern. Das wiederum setzt die Existenz von praxisbewährten Ontologien und Wörterbüchern voraus. Auf ihrer Basis kann eine automatische Annotation von Texten aller Art erfolgen!
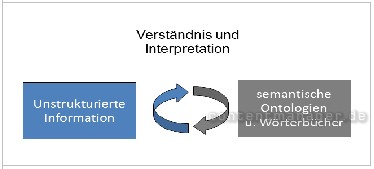 Grafik 6: (semi-)automatische Annotation mittels Ontologien und Wörterbüchern
Grafik 6: (semi-)automatische Annotation mittels Ontologien und Wörterbüchern
Unstrukturierte, also chaotische Information kann mit Hilfe semantischer Software (semi-)automatisch in strukturierte und damit interpretierbare Information umgewandelt werden. Voraussetzung dafür ist kontextspezifisch aufbereitetes Fachwissen in Form von Ontologien, Taxonomien und Wörterbüchern. Texte, die noch keine RDF-Annotation besitzen, können auf dieser Basis automatisiert mit Metadaten aufgewertet und anschließend wesentlich besser verstanden bzw. interpretiert werden.
(Semi-)automatische Annotation ist auf unterschiedliche Weise realisierbar. Schon heute gibt es gute Lösungen. Es ist zudem zu erwarten, dass entsprechende Systeme in kurzer Zeit erhebliche Qualitätssprünge vollziehen werden. Entsprechende Tools können an die meisten Communities bzw. Daten-Crawler angedockt werden, um Inhalte selbständig zu annotieren!
Erforderlich sind dafür mindestens drei wichtige Bausteine:
- kontextspezifische Ontologien, Taxonomien bzw. Wörterbücher als Basis automatischer Annotation
- eine semantische Software, die verschiedene Ontologien, Taxonomien und Wörterbücher sinnvoll priorisieren, vernetzen und anschließend verarbeiten kann (z.B. basierend auf einem mehrstufigen neuronalen Netz)
- passende Schnittstellen und Standards im Hinblick auf die semantische Software und dem System das Quell- und Zielinformation enthält (z.B. SOAP)
Selbst wenn alle Softwareprobleme gelöst sind bleibt die Frage: Woher sollen die Ontologien, Taxonomien und Wörterbücher kommen? Die Erstellung dieser semantischen Basiselemente ist ein aufwändiger und zudem urheberechtlich geschützter Prozess.
Wird der Aufwand durch diesen Ansatz also nur von einer Ecke in die andere verlagert?
Nein! Die Lösung könnte auch hier in einer automatisierten Erstellung von Ontologien, Taxonomien und Wörterbüchern liegen – vorausgesetzt, dass man die Rechte am dafür erforderlichen „Rohmaterial“ besitzt: An weitgehend strukturierten digitalen (Fach-)Texten!
Mega-Quelle für Ontologien: Digitale Fachbücher!
Vermutlich halten Verlage, Bibliotheken und Universitäten den Schlüssel zur effizienten Erstellung semantischer Basisprodukte bereits in Händen: Sie besitzen nämlich nicht nur die digitalen Daten von Artikeln, Fachbüchern, Fachzeitschriften und Diplomarbeiten, sie verfügen auch über die diesbezüglichen Nutzungsrechte!
Zudem halten sie noch zwei weitere Trümpfe in Händen:
Zum einen haben Softwarehersteller keinerlei Kernkompetenz bgzl. der inhaltlichen Erstellung von Ontologien, Taxonomien und Wörterbücher zu unzähligen Fachthemen – sie sind auf diesbezügliche Hilfe von Experten angewiesen (z.B. zu den Themen Recht, Informatik, Chemie, Maschinenbau etc.)! Zum anderen eignen sich gerade Fachbücher und Diplomarbeiten zu diesen Themen ideal für eine (halb-)automatische Annotation. Gleiches gilt für Zeitschriftenartikel (egal ob Print oder Online), da diese häufig den neuesten Stand eines fachlichen Themas widerspiegeln und so laufende thematische Entwicklungen aufgreifen können.
Entsprechende Texte verfügen jedenfalls über einen hohen Grad der Vorstrukturierung! Zudem werden innerhalb dieser Texte die sprachlichen Regeln überdurchschnittlich genau beachtet, weshalb sie mit entsprechenden Tools und Grundwörterbüchern bestmöglich „semantisch veredelt“ werden können! So entsteht ein mehrstufiger Prozess der von strukturierten Inhalten ausgehend das Chaos schrittweise automatisiert aufzulösen vermag.
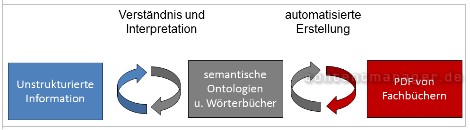 Grafik 7: Prozess der automatischen Erstellung von Ontologien aus Fachbüchern
Grafik 7: Prozess der automatischen Erstellung von Ontologien aus Fachbüchern
Von rechts ausgehend: Wer über ein maschinenlesbares Fachbuch als PDF verfügt, kann damit schon heute (halb-)automatisch Ontologien , Taxonomien und semantische Wörterbücher erstellen. Anschließend können die Ergebnisse ihrerseits zur automatisierten Interpretation von unstrukturierten Inhalten dienen. Die derart umgewandelte Information kann schließlich durch selbstlernende Methoden als Referenzwissen zur weiteren Auflösung des gordischen „Semantik-Knotens“ dienen.
Auch wenn automatisch erstellte Basisprodukte im Einzelfall eine manuelle Nacharbeit bzw. eine Qualitätssicherung erfordern: Automatisierung hilft dabei den Erstellungsaufwand drastisch zu reduzieren! Voraussetzung ist allerdings stets, dass man über vorstrukturiertes und digitalisiertes Ausgangsmaterial z.B. im ASCII-Format sowie über die entsprechenden Nutzungsrechte verfügt.
Neben den Verlagen gibt es gegenwärtig wohl nur eine Quelle, die über eine entsprechende Menge digitalisierter Fachbuchinhalte verfügt: Google-Books ! Vermutlich war es beim Start dieses Services nicht das Ziel, die dort erfassten PDF später einmal zu fachlichen Ontologien, Taxonomien und Wörterbüchern zu verarbeiten – aber heute und morgen ist es möglich und mutmaßlich auch sinnvoll bzw. ein potenzielles Geschäft! Mit den Inhalten von Google-Books und einer semantischen Community wie Freebase / Metaweb verfügt Google jedenfalls schon heute über die vielleicht wichtigsten Voraussetzungen für eine umfassende (semi-)automatische Erstellung semantischer Basisprodukte!
Chance für Verlage
Angenommen, die Verlagswelt wollte aus dem semantischen Potenzial ihrer Fachbücher, Zeitschriften und sonstigen digitalen Daten selbst ein Geschäft machen: Dann erfordert dies nicht nur ein Produktangebot, sondern auch eine entsprechende Nachfrage – benötigt wird also ein Markt. Einen, den es so noch nicht gibt! Das Geschäft mit Metadaten etc. wird zwar schon lange geprüft, aber die Ergebnisse sind bislang dürftig. Häufig wird darauf hingewiesen, dass niemand bereit sei , für entsprechende Information zu zahlen. Werden Chancen für Verlage hervorgehoben, dann geht es daher meist um den Vorteil des schnelleren Findens von digitalen Verlagsprodukten im Semantic Web, aber nicht um Erlöse durch Verkauf von semantischen Basisprodukten wie einer Ontologie, einer Taxonomie oder einem Fachwörterbuch.
Die Frage ist daher berechtigt, ob es einen solchen Markt überhaupt in absehbarer Zeit geben kann. Wer Antworten sucht, muss beim bereits existierenden Bedarf der Gegenwart beginnen, die weitere Entwicklung abschätzen und mit der Suche nach Alternativlösungen abschließen!
Praktischer Bedarf an semantischen Basisprodukten besteht schon heute überall dort, wo unstrukturierte Information bewältigt werden muss, aber manuell nicht (mehr) effizient oder schnell genug bewältigt werden kann! Das ist im Bereich des Social-Media-Monitoring (inkl. Freakwave-Detection, s.o.) ebenso der Fall wie beim Beschwerdemanagement (Tsunamis, s.u.) und der Enterprise-Search (Mahlstrom, s.u.). Darüber hinaus gibt es noch eine Reihe weiterer Themen, bei denen semantische Grundprodukte zur Bewältigung unstrukturierter Information eingesetzt werden könnten!
Wie das unglaubliche Wachstum des Semantic-Spezialisten Autonomy belegt, ist der diesbezügliche Bedarf ebenfalls extrem am Wachsen! Gleichwohl werden semantische Basisprodukte nach wie vor entweder manuell oder kundenindividuell mit Tools von Software-Herstellern erstellt. Außen vor bleiben aber die eigentlichen Sprach- bzw. Fachexperten, nämlich die Verlage!
 Grafik 8: Prozesse mit unstrukturierter Information in Unternehmen
Grafik 8: Prozesse mit unstrukturierter Information in Unternehmen
Für Unternehmen macht es kaum Sinn, für jeden Prozess eine eigene semantische Software-Lösung zu betreiben (z.B. nur für eDiscovery und nur für Enterprise-Search). Die Heterogenität der IT-Systemlandschaft würde dadurch noch höher, zudem können bei zersplitterten semantischen Lösungen keine übergreifenden, also unternehmensweiten Lernprozesse erzielt werden. Sinnvoller sind zentrale semantische „Backbones“ bzw. Annotatoren, die über Schnittstellen an unterschiedliche IT-Systeme angedockt und mit kontextspezifischen Ontologien und Wörterbüchern unterschiedlicher XML-Standards „veredelt“ werden können. </center>
Ein modulares semantisches System bietet vor allem für den Endanwender (z.B. Unternehmen) große Vorteile: Es ermöglicht unternehmensübergreifende Lernprozesse und spart semantische Ressourcen und damit im erheblichen Umfang Kosten. Durch Zusammenstellung, Kombination und Ergänzung semantischer Basisprodukte können Unternehmen zudem individuelles Wissen auf- und ausbauen. Entsprechende Ansätze (z.B. Corporate Ontologie Management ) scheitern bislang aber häufig daran, dass es trotz vorhandenem Bedarfs keinen Markt und damit auch keine standardisierten Basisprodukte gibt – zu viel wird bislang individuell und damit letztendlich ineffizient gelöst.
Das skizzierte Model öffnet der Verlagswelt die potenzielle Chance, von der immer dringender werdenden Bewältigung semantischer Aufgaben innerhalb von Unternehmen und Organisationen sowohl mittel- als auch langfristig zu profitieren. Die Vorteile dieses Ansatzes werden noch deutlicher, wenn man zwei zusätzliche Prozesse unstrukturierter Information näher untersucht: Beschwerdemanagement und Enterprise-Search.
Tsunami: Die Anfrage- und Beschwerdenflut!
Beispiele für zunehmende Informationsfluten finden sich überall – insbesondere bei Anfragen und Beschwerden! Bei den Verbraucherzentralen sind z.B. im Jahr 2010 rund 80.000 Beschwerden allein wegen unerlaubter Telefonwerbung eingegangen. Bei 250 Arbeitstagen pro Arbeitskraft bedeutet dies, dass man bei fünf Minuten Erstbearbeitung je Beschwerde drei geschulte Mitarbeiter im Jahr benötigt, um die Beschwerden lediglich zu lesen, also zu verstehen – das Erstellen dazugehöriger Antworten ist noch gar nicht berücksichtigt!
Insbesondere Beschwerden haben eine weitere Tücke: Sie sind nicht gleichmäßig über das Jahr verteilt, Beschwerden erscheinen vielmehr in Form von Peaks! So gesehen ist mancher Beschwerdeanlass eine Art tektonisches Beben, dem in kürzester Zeit ein regelrechter „Tsunami von Beschwerden“ nachfolgt. Einen solchen Tsunami kann es natürlich genauso im Positiven geben: Bei einer Flut von Kundenfragen. Das Problem bleibt jedoch das Gleiche!
Quelle 20min.ch :
Alleine in Zürich gingen am ersten Tag 37 000 Anrufe ein. „Um diesen Andrang zu bewältigen, bräuchten wir 2500 Mitarbeiter“, sagt der Chef des Zürcher Passbüros, Peter Klossner. „Es ist ein wahrer Tsunami über uns hereingebrochen.“
Gleich ob schriftlich, per Mail und/oder telefonisch: Entsprechende Flutwellen erfolgen fast nie im Wege gleichmäßiger Verteilung, sondern überraschend. Gehen sie als Mail ein oder werden sie mittels Text2Speech in Text umgewandelt, können sie in vielen Fällen auf Basis semantischer Technologie inhaltlich klassifiziert werden:
- Welches Thema hat die Beschwerde/Anfrage?
- Welcher Abteilung ist sie zur weiteren Bearbeitung zuzuordnen?
- Welche Vorab-Antwort würde zur Beschwerde/Anfrage passen?
Selbst dann, wenn eine semantische Softwarelösung nur 50% eines solchen Tsunami filtert, kanalisiert und klassifiziert, hat dies eine erhebliche Erleichterung zur Folge!
- es entstehen erhebliche personelle Entlastungen
- es entsteht ein gewaltiger Zeitgewinn für die restlichen Beschwerden
- es entsteht ein relevanter Imagegewinn durch schnellere Reaktion
- es werden in hohem Umfang Kosten eingespart
Leider fehlt Beschwerden bzw. Anfragen das Wichtigste für die automatische Interpretation: Es fehlen semantische Metadaten, da der Absender diese nicht mit auf den Weg gibt und geben kann. Es muss also erneut eine automatische Annotation von Texten erfolgen. Wie dies grundsätzlich erfolgen kann wurde zuvor bereits skizziert (s.o). Sicher ist: Mittels semantischer Technologie kann das Thema auf ein deutlich höheres automatisiertes Niveau gehoben werden. Allerdings sollte man beachten, dass semantische Mittel nicht ausschließlich die Aufgaben des Menschen übernehmen können und sollen. Vielmehr unterstützen sie bisherige Verfahren und heben damit das Qualitätsniveau an.
Information im Mahlstrom finden
Ähnlich liegt der Fall im Bereich der Enterprise-Search : Mitarbeiter verbringen immer mehr Zeit damit, Dokumente oder deren Inhalte (erfolglos) zu suchen. Auf den unzähligen Unternehmens-Servern verschwindet so manches File in einem digitalen Strudel ohne Wiederkehr – in einem Mahlstrom . Auch hier wird seit langem mit semantischen Methoden gearbeitet, um Suchergebnisse signifikant zu verbessern. Allerdings gilt erneut: Kaum ein Text bzw. Dokument verfügt über semantische Metadaten. Schon wieder kommt es zur Notwendigkeit automatischer Annotation als Vorstufe der weitergehenden Interpretation!
Bei der Enterprise-Search kommen kontextspezifische Besonderheiten erschwerend hinzu: Aufgrund abteilungsspezifischer Suchanforderungen reicht es nur selten aus, mit einem generell-probabilistischen „Basiswissen“ zu arbeiten, um gute Ergebnisse zu erzielen: Während eine Marketing-Abteilung die Datenbasis mit Suchbegriffen aus ihrem Fachgebiet durchforstet, macht es die Personalabteilung mit dem eigenen Fachvokabular etc. Insofern bietet sich eine abteilungsspezifische Verwendung von Fachontologien, Fachtaxonomien und Fachwörterbüchern an, um die Suchergebnisse für die Präferenzen des Suchenden bestmöglich zu optimieren.
Natürlich ist es am besten, wenn ein Unternehmen eigene Ontologien, Taxonomien und Wörterbücher integrieren kann (z.B. durch Umwandlung eigener Textvorlagen oder durch Training). Bevor es dazu kommt, wäre allerdings in vielen Fällen die Verwendung bereits existierender semantischer Basisprodukte aus dem Verlagsbereich nicht nur ein enormer Startvorteil – es ist auch gerade im Hinblick auf die Zukunft eine investitionssichernde Garantie für die Aktualität des Gesamtsystems! Mit Standardprodukten wird eine dauerhafte Mindestqualität garantiert und zudem der Einstiegsaufwand erheblich verringert!
Universeller semantischer Backbone
Der übergreifende Synergie-Effekt bei der Bewältigung der drei zuvor skizzierten nautischen Herausforderungen „Freakwave“, „Tsunami“ und „Mahlstrom“ liegt zum einen darin, dass für alle drei Aufgaben im Grunde nur ein einziger zentraler semantischer Backbone erforderlich ist. Einer, der an verschiedene IT-Systeme angeschlossen wird, aber kontextspezifisch unterschiedliche Ergebnisse liefern bzw. Aufgaben erledigen kann.
Ein weiterer Synergie-Effekt liegt in der mehrfachen Verwendung verschiedener Fachwörterbücher z.B. bei der Enterprise-Search und beim Beschwerdemanagement. Trotz unterschiedlicher Prozesse können nämlich die dort verarbeiteten Textinhalte deutliche Überlappungen besitzen: Kunden werden sich z.B. regelmäßig über Produkte oder Abteilungen eines Unternehmens beschweren und daher solche Begriffe nutzen, die gleichermaßen intern und extern Gültigkeit haben. Überschneidungen gibt es aber auch zwischen Beschwerdemanagement und dem „anarchischen“ Vokabular des Web 2.0, denn Kundenbeschwerden werden nicht unbedingt sorgfältiger formuliert als ein öffentliches Posting auf einer Community.
Warum sollte man also alle Prozesse und Systeme doppelt und dreifach und zudem isoliert voneinander aufsetzen, wenn das Synergiepotenzial so erheblich ist?
Dafür gibt es mehrere Gründe:
- Der Markt für semantische Basisprodukte fehlt (Angebot und Nachfrage)
- Softwarehersteller arbeiten (noch) nicht an einer Lösung für Basisprodukte
- Die bisherigen Computer- und Betriebsystemgenerationen waren schlicht überfordert derartige Datenmenge zu verwalten
Erst mit der Einführungen der neuen Prozessor- und Betriebsystemgenerationen (64-bit) ist eine effektive semantische Suche überhaupt erst möglich. Durch CloudComputing und MultiThreading sind heute Dimensionen erreichbar, welche vor wenigen Jahren nicht denkbar waren.
Mehrwerte durch semantische Verlagsprodukte
Den marktbezogenen Stillstand könnten vor allem Verlage durchbrechen, in dem sie den Markt für semantische Ontologien, Taxonomien und Fachwörterbücher überhaupt erst einmal erkennen und Produkte entwickeln, die ähnlich einer Loseblatt-Sammlung inklusive regelmäßiger Updates funktionieren: Ein und das gleiche semantische Marketing-Wörterbuch kann dann in unzähligen Firmen stets aktuell eingesetzt werden. Für Verlage ist die Erstellung dieser Produkte zum einen verhältnismäßig effizient möglich, darüber hinaus könnten die Ontologien vom Fachmann, nämlich dem Autor, zusätzlich manuell verifiziert bzw. aktualisiert werden. Schließlich haben Verlage auch bestehende Vertriebswege, um entsprechende Produkt zu vertreiben.
Durch „digitale Massenproduktion“ würden die Kosten entsprechender Ontologien deutlich sinken, was wiederum die Nachfrage forcieren würde. Die Produkte müssen auch nicht als offenes XML ausgeliefert werden, vielmehr sind Dateiformate vorstellbar, die ein unerlaubtes Kopieren semantischer Basisprodukte verhindern.
Es bleibt daher die Frage, wie man diesen Prozess in Gang bringen kann. Zunächst wird sich ein „Henne-Ei“-Problem ergeben: Softwarehersteller werden auf die Verlage verweisen und umgekehrt. Dies könnte auch noch eine Weile so bleiben, aber es scheint ein Ende in Sicht, da der faktische Druck in Richtung einer solchen modularen Lösung wächst!
Prognose für die Zukunft
Weder Idealismus noch die intellektuelle Einsicht werden einen entsprechenden Druck zur Annäherung von Verlagen und Softwareherstellern zu bewirken. Es werden wohl eher schmerzhafte Extreme und ihre Folgen sein, die das Rad zum Rollen bringen: Durch zunehmende Schäden von „Freakwaves“, „Tsunamis“ und dem „Mahlstrom“ wird sich vermutlich recht bald eine hochleistungsfähige semantische Gesamtlösung herausmendeln, die u.a. zwei wichtige Aspekte verbindet:
- am effizientesten ist ein universeller semantischer Technologie-Backbone, der für verschiedene interne und externe Prozesse der Endkunden die Möglichkeit bietet „rohe“ Texte aller Art automatisch zu annotieren bzw. zu klassifizieren
- die dafür notwendigen semantischen Basisprodukte werden von denen erstellt und vertrieben, die über das größte Potenzial an digitalen Fachinhalten verfügen: Die Verlage!
Ein Vergleich mag das Erfolgsgeheimnis verdeutlichen:
In den 70er und 80er Jahren hat sich beim “ Krieg der Videosysteme “ die Technologie durchgesetzt, die die meisten vorbespielten Videos in Videotheken anbieten konnte. Die Möglichkeit, selbständig Aufnahmen von Fernsehsendungen zu machen, war zwar auch wichtig, aber nicht kriegsentscheidend. Der Sieg von VHS war umfassend, obwohl das Format bei weitem nicht die beste Technik besessen hat: Es war einfach das bessere Gesamtangebot und damit die bessere Strategie!
Zeit für neue Wege!
Damit zum abschließenden Statement dieses Dreiteilers: Semantische Software ist nicht neu – ihr Ursprung reicht zurück in die 80er Jahre. Getrieben wurde die semantische Vision lange Zeit von Idealismus und Faszination. Selbst das Ziel eines semantischen Web hat über Jahre hinweg eine überwiegend akademische Handschrift getragen. Zudem war das semantische Geschehen lange Zeit ein eher zufälliger Prozess von Trial-and-Error!
Gott sei Dank! Gerade aufgrund des empirischen Vorgehens sind unzählige Erfahrungen gesammelt und wichtige technologische Erfolge erzielt worden. Gleichwohl entwickelte sich vieles unzusammenhängend, also inselhaft – dies gilt es für die Zukunft zu ändern! Die bisherige Insel-Vision des Semantic-Web reicht für die erforderliche übergreifende Lösung nicht aus. Das Internet ist eben nur einer von unzähligen Bereichen, in denen semantische Technologien wertvolle Hilfe bieten können, allerdings einer der wichtigsten.
Es muss ein übergreifendes Konzept her, das die bisherige Strategie de Semantic-Web integriert und erweitert! Eines, dass Anwendungsszenarien für Unternehmen berücksichtigt und eines, das den wichtigsten Erfolgsfaktor ins Zentrum stellt: Das kontextspezifische Sprachverständnis auf Basis automatischer Annotation.
Benötigt wird dafür inhaltliche Vielfalt und deshalb ein Markt für universell einsetzbare semantische Basisprodukte. Diesbezüglich führt wohl kaum ein Weg an den Verlagen vorbei. Benötigt werden aber auch flexible semantische „Technologie-Backbones“, die auf Grundlage dieser Produkte Texte aller Art automatisch annotieren bzw. kontextspezifisch interpretieren können.
Ganz gleich, wie die bestmögliche Lösung irgendwann einmal aussieht, folgendes ist schon heute klar: Technologie allein wird nicht der Schlüssel intelligenter Software sein! Genauso wichtig ist die effiziente semantische Aufbereitung einer sich permanent ändernden Sprache!
Wer das noch unbeackerte Feld einer übergreifenden Lösung erfolgreich bestellt, derjenige hilft bei der Bewältigung dringlich werdender Herausforderungen! Denjenigen erwartet genau deshalb ein gutes Geschäft!
In diesem Sinne: „Lets get ready to rumble!“




{kind=link}
{kind=link}
{kind=link}
{kind=link}
No Comment