

Semantische Software kann den Inhalt von Texten analysieren und darauf basierend Dokumente klassifizieren. Wie funktioniert das? Im nachfolgenden zweiten Teil erfolgt ein Überblick über semantische Technologien.
Die Firma Aral präsentierte in den 70er Jahren einen ungewöhnlichen Werbespot. Darin wird ein schnödes Schmiermittel als Motoröl mit „chemischen Gehirn“ vorgestellt. Das Gleichnis war fraglos eine dreiste Lüge. Öl kann nicht denken! Fast möchte man meinen, dass dieser Spot Loriot zu seinem Klassiker „Der sprechende Hund“ inspirierte.
Wie ist es nun bei semantischer Software?
Kann sie denken? Zusammenhänge erkennen? Falls ja: Wie? Und wo sind die Grenzen?
Sicher ist: Aufgrund des großen Bedarfs an intelligenter Software waren und sind nicht nur seriöse Anbieter unterwegs. Mitunter wird – wie bei Loriot – ganz selbstbewusst mehr versprochen als gehalten werden kann. Bei den nahen Verwandten semantischer Technologie, den neuronalen Netzen, sind sogar Betrugsfälle bekannt. Dank Web 2.0 fliegen solche Mogelpackungen jedoch immer öfter auf.
Lapidar könnte man dazu sagen „wo Licht ist, ist auch Schatten“. Doch umso mehr darf man sich fragen: „Wie hell leuchtet die semantische Birne wirklich?“ Hier hilft ein Blick in die Technik, um belastbare Grundaussagen zu treffen.
Die Kunst, Zeichen zu deuten
Semantik ist die Lehre von der „Bedeutung der Zeichen“. Zeichen im Sinne der Semantik kann dabei so ziemlich alles sein: Buchstaben, Hieroglyphen, ASCII-Text oder einfach nur Dreiecke, Kreise und Quadrate.
Zeichen im Sinne semantischer Software sind auch Dreiecke und Quadrate
Für einen Computer sind alle Zeichen gleichwertig. Bedeutung erhalten Zeichen erst durch Regeln (z.B. Syntax). Bei der Morse-Sprache können zum Beispiel durch die Kombination von Regeln und simplen Zeichen hoch komplexe Aussagen kodifiziert werden: Am Ende bleibt es aber eine intelligente Kombination von Punkten und Strichen.
Semantische Software interpretiert ASCII-Text Zeichen. Sie basieren auf einer Codesprache auf Byte-Ebene. Computersprachen wie C++, JAVA, Perl etc. nutzen ebenfalls ASCII-Symbole. Eine Software, welche die Bedeutung von ASCII-Zeichen deutet, ist daher etwas ganz Normales: Jeder Software-Kompiler muss tausende Zeilen Code mit abertausenden Zeichen interpretieren, analysieren und verstehen, damit daraus am Ende ein funktionsfähiges Programm wird.
Entwicklungsumgebung für JAVA als „semantische Software“
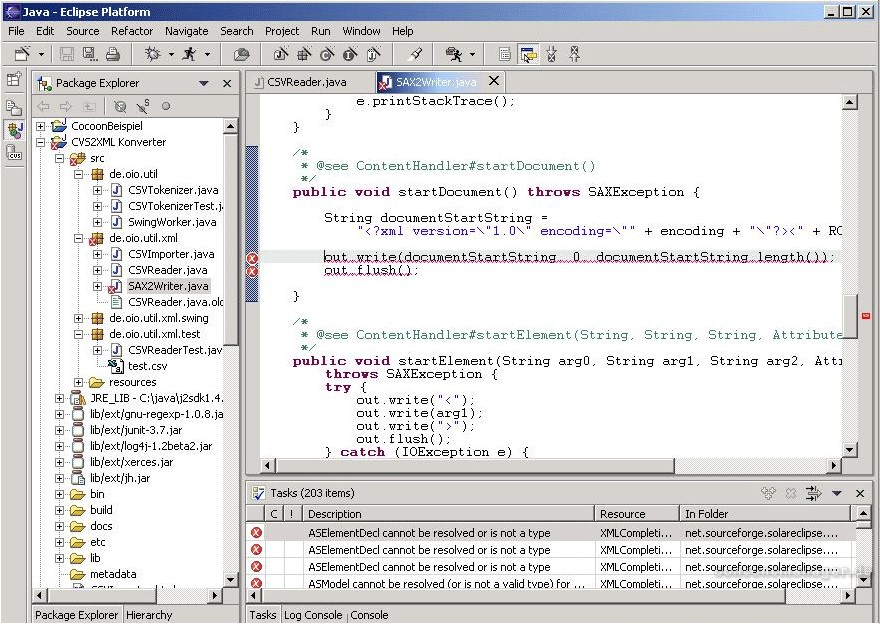
Eine JAVA-Entwicklungsumgebung wie Eclipse „versteht“ String-basierte Programmiersprachen im Zweifel so gut, dass ein Debugger Hinweise gibt, falls Fehler im Quellcode enthalten sind – Fehler, die der Programmierer (als Mensch) nicht von selbst erkannt hat. Die „Text-Editoren“ nutzen dazu ASCII-Zeichen. Dem Grunde nach ist daher jeder Kompiler eine Art semantische Software: Er kann selbständig Zeichen und Zeichenfolgen interpretieren und daraus Schlussfolgerungen ziehen.
Dass Software eine regelbasierte Folge von ASCII-Zeichen verstehen kann, ist also per se nicht so revolutionär wie man auf den ersten Blick denken könnte. Der Trick: Softwarekompiler interpretieren Quellcode in einem geschlossenen System. Ein solches System setzt eindeutige Regeln voraus und ermöglicht damit auch eindeutige Schlüsse!
Im Sinne der semantischen Interpretation wird es deshalb dort spannender, wo Software genutzt wird, um „lebendige“ und damit nicht geschlossene Systeme zu verstehen. Das sind Systeme die eine Eigengesetzlichkeit besitzen, zum Teil nicht-linear verlaufen und/oder sich permanent weiter entwickeln.
Ein zumindest halboffenes System ist die IT-Infrastruktur z.B. von einem Krankenhaus. Während die jeweils einzelne Software (für Bettenbelegung, Warenlieferung und Abrechnung etc.) für sich selbst ein geschlossenes System bildet, gilt dies nicht unbedingt für das übergreifende Zusammenspiel der IT-Systeme untereinander: Die Summe aller Einzelsysteme ist ein wachsender, quasi lebendiger und damit auch leicht chaotischer Organismus. Hilfe bietet hier z.B. die semantische Software der Fa. Model-Labs : Sie identifiziert Schnittstellen und erstellt dazu selbständig passende Codes. Entsprechende Lösungen können die Kosten einer Systemintegration erheblich reduzieren.
Semantische Software für die Integration von Software-Systemen
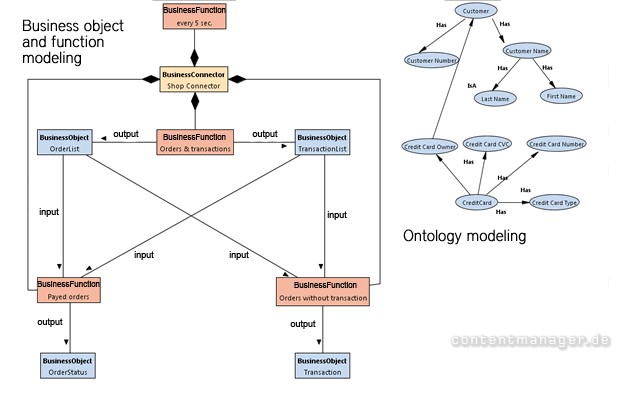
Bei der Integration von IT-Systemen liegen schon begrifflich mehrere (z.T. eigengesetzliche) Systeme vor. Es gilt, diese bestmöglich zu integrieren. Zwar beruhen die Einzel-Systeme auch auf der Verwendung einer künstlichen Sprache (= C++, JAVA, Dot.net etc.). Da der Mensch diese Systeme jedoch unabhängig voneinander und empirisch aufsetzt, kommt es häufig zu „nichtlinearen“, ja geradezu chaotischen Verläufen der Systeme untereinander: Hier können semantische Software-Lösungen wie die von Modul-Labs helfen, automatisiert Ordnung ins Chaos zu bringen: Dazu werden z.B. bei Schnittstellen die relevanten Übergabeparameter (Variablen = Zeichenfolgen) erfasst und automatisiert miteinander in eine strukturierte Relation gebracht (Matching). Selbst der Code wird dabei automatisch erstellt.
Halboffene Systeme sind bereits wesentlich komplexer als geschlossene Systeme. Aber so richtig herausfordernd wird es erst bei stark unstrukturierten Systemen wie der natürlichen Sprache. Die hinter ihr liegenden Regeln sind über Jahrhunderte historisch gewachsen, mitunter sind sie nur implizit und damit unscharf. Aber noch schlimmer: Obwohl unzählige Regeln vorhanden sein können, werden sie von Autoren nicht immer konsequent beachtet – mal unbewusst, mal absichtlich! Zudem hat die natürliche Sprache nicht nur einen faktischen, sondern einen ebenso wichtigen sozialen Zweck: Wut, Freude, Wahrheit und Lüge sind nur einige der Dimensionen, die es beim menschlichen Sprachgebrauch zu beachten gilt.
Systemcharakter natürlicher und künstlicher Sprachen
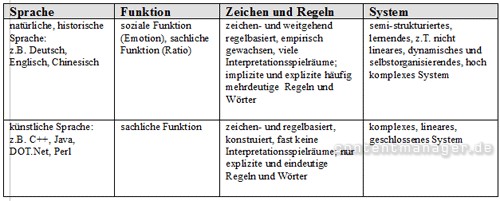
Kunstsprachen sind perfekt kontrollierbar, daher sind sie auch eindeutig interpretierbar. Ganz anders die historischen bzw. natürlichen Sprachen: Sie besitzen neben der sachlichen Funktion auch eine soziale Dimension. Sie sind extrem facettenreich und zudem im permanenten Fluss. Die Interpretation entsprechender Zeichen ist hoch komplex. Bei semantischer Software im eigentlichen Sinn geht es darum, eine natürliche Sprache durch eine computerbasierte Kunstsprache zunächst zu erfassen und anschließend zu deuten.
Computer-Linguistik
Damit Software eine natürliche Sprache überhaupt interpretieren kann, ist zunächst ein linguistisches Grundverständnis des Computers erforderlich. Bereits lange bevor die Idee des Semantic Web geboren wurde, haben sich Informatiker mit der Lösung dieser Frage auseinander gesetzt. Schon in den frühen 80er Jahren entstanden die ersten Gesellschaften zur linguistischen Datenverarbeitung . Sie schafften die entsprechenden Grundlagen der heutigen Computerlinguistik . Diese Wissenschaft transferiert die Gesetze der sprachlichen Grammatik in Richtung des Computers. Typische Themen sind dabei:
- Wortklassifikation (Subjekt, Prädikat, Objekt)
- Wortableitungen (Lemmata = z.B. gebe, gibst, gibt)
- Synonyme („richtig“ = „korrekt“)
- Zeitformen (Präsens, Vergangenheit)
- Wortsegmentierung („Pferdestall“ = „Pferde“+“Stall“)
- Positiv/Negativ-Analyse („ich bin müde“ vs. „ich bin nicht müde“)
Begriffs-Dimensionen
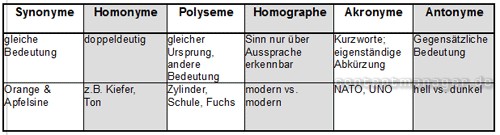
Welche linguistischen Dimensionen hinter nahezu jedem Begriff einer natürlichen Sprache stehen, kann man bereits an dieser Tabelle erahnen: Eine semantische Software muss all diese Zusammenhänge kennen und prüfen, um einen einzelnen Begriff zu bewerten bzw. zu klassifizieren. Allein die Aufstellung entsprechender Regeln ist eine Wissenschaft für sich! Die Interpretation von Langtexten mit tausenden von Worten und zehntausenden Buchstaben lässt zudem erahnen, welche Rechenleistung zur Interpretation von Begriffen, Sätzen oder gar Kapiteln erforderlich ist.
Die Computerlinguistik hat in den letzten Jahren nicht nur aufgrund neuer Algorithmen enorme Fortschritte gemacht. Eine wichtige Rolle spielen dabei auch die immer schneller werdenden Computer und leistungsfähigere Speicher. Mit Rechnern der neusten Generation können daher mittlerweile sehr komplexe mehrstufige Prozess-Schritte effizient bearbeitet werden. Texte von vielen tausend Zeichen sind mittlerweile im Millisekundenbereich mehrdimensional auswertbar. Mitunter kann durch Auslagerung von semantischen Rechner-Prozessen auf Grafikkarten sogar noch mehr Speed erzielt werden ( OpenCL / CUDA ).
Verständnisgrundlage: „Weltwissen“
Semantische Software wird oft mit dem komplexesten Speichermedium überhaupt verglichen: Dem menschlichen Gehirn – letztlich soll sie ja auch ähnliches leisten. Die Speicherleistung ist und bleibt vor diesem Hintergrund auch in Zukunft ein Schlüsselfaktor. Die semantische Software muss nämlich nicht nur den zu bearbeitenden Text analysieren, der Computer muss zugleich auch das eigene „Weltwissen“ der Software aktivieren – hier kann es sich um hoch komplexe Datenbanken mit Synonym-Wörterbüchern, Regelwerken und Thesauren handeln.
Weltwissen und zu interpretierender Text
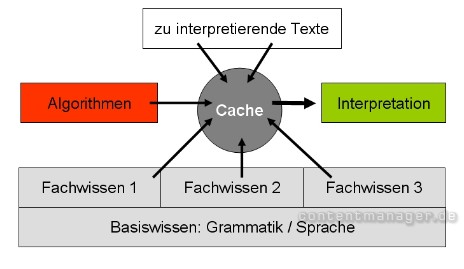 Im Cache des Computers wird bei der semantischen Text-Analyse ein hoch komplexer Cocktail aufbereitet: Neben der algorithmischen Logik müssen die zu interpretierenden Texte, aber auch die zur Interpretation erforderlichen Wissenselemente zur Laufzeit verarbeitet werden. Neben dem „Basiswissen“ ist dabei in der Regel auch ein zusätzliches „Fachwissen“ erforderlich, da z.B. ein „Amboss“ ein Schmiedewerkzeug, ein Musikinstrument oder aber ein Knochen im Ohr sein kann. Ein musikalisches Wörterbuch wird daher in der Medizin nur Verwirrung stiften und umgekehrt.
Im Cache des Computers wird bei der semantischen Text-Analyse ein hoch komplexer Cocktail aufbereitet: Neben der algorithmischen Logik müssen die zu interpretierenden Texte, aber auch die zur Interpretation erforderlichen Wissenselemente zur Laufzeit verarbeitet werden. Neben dem „Basiswissen“ ist dabei in der Regel auch ein zusätzliches „Fachwissen“ erforderlich, da z.B. ein „Amboss“ ein Schmiedewerkzeug, ein Musikinstrument oder aber ein Knochen im Ohr sein kann. Ein musikalisches Wörterbuch wird daher in der Medizin nur Verwirrung stiften und umgekehrt.
Speziell im Deutschen Raum hat sich schon zu Anfang der 90er Jahre die Idee des „Weltwissens“ gebildet: Dabei handelt es sich etwas flapsig formuliert um ein Breitenwissen, das man vielleicht einem Abiturienten unterstellen sollte: „Wer war Bismarck?“, „Wann wurde Adenauer Bundeskanzler?“, „Was ist ein Adjektiv?“, „Wie oft war Deutschland im Halbfinale einer Fussballweltmeisterschaft“ etc.
Wie insbesondere die letzte Frage zeigt, ist das Weltwissen dynamisch. Ein Wörterbuch von 1970 wird folglich andere Ergebnisse liefern als eines von 2010. Zudem liefert es bei speziellen Fragestellungen nur oberflächliche Hilfe: Es muss je nach Aufgabe um vertikales Fachwissen erweitert werden können. Aus diesem Grund wird immer häufiger auf dynamische Wissenquellen wie Wikipedia und zusätzliche Fachlexika zurück gegriffen, um Textinhalte akkurat semantisch zu interpretieren.
Ein aktuelles Beispiel für eine auf Wikipedia basierende Konstruktion findet sich in einem Fachbeitrag vom Spektrum der Wissenschaft . Ähnlich sieht es beim Google-Ansatz aus: Beim diesbezüglichen semantischen Ansatz wird allerdings auf die Wissensbasis von MetaWeb zurück gegriffen.
Semantische XML-Standards
Quellen wie Wikipedia liefern bislang zwar Wissen, aber nur bedingt ein semantisches System, um die dort enthaltene Information entsprechend zu analysieren. Aus diesem Grund wurde das Gemeinschaftsprojekt „dbpedia“ ins Leben gerufen. Dabei geht es darum, Wikipedia-Information in das semantische XML-Format „RDF“ zu übertragen und damit noch besser interpretierbar zu machen. Dies gelingt aufgrund der Verwendung von standardisierten Metadaten, die den Haupttext und seinen Sinn ergänzen und damit die Interpretationbreite einengen.
Das XML-Format „RDF“ liegt schon seit den 90er Jahren der Idee des Semantic Web von Tim Berners-Lee zugrunde. Für alle diesbezüglichen Entwicklungen im Web bildet es wohl auch in Zukunft das Rückgrat.
Deutung von Begriffen durch semantische Standards
Wie semantische Standards funktionieren verdeutlicht eindrucksvoll dieser Film über die Funktionsweise von MetaWeb auf Youtube . Ob ein User beim Verwenden des Begriffs „Boston“ an die Musiker oder die Stadt (bzw. welche) gedacht hat, kann in Metadaten abgelegt und damit später nachvollziehbar gemacht werden.
Das RDF-Schema ist dabei nur die halbe Lösung für Verständnis: Um umfassendere Schlüsse zu ermöglichen muss es zusammen mit einer sog. Ontologie verwendet werden. Die Ontologie hat dabei vornehmlich die Aufgabe, Begrifflichkeiten und ihr Verhältnis zueinander zu regeln. Beispiel: „Welches Verhältnis besteht zwischen Wurzel, Ast und Baum?“ Diese Information ist meist nicht in RDF’s enthalten. Dafür gibt es einen eigenen XML-Standard: Das sog. OWL-Format . Mit ihm werden Zusammenhänge zwischen verschiedenen Inhalten nach definierten Regeln dokumentiert.
Sind entsprechende Standards eingehalten, gelingt semantischer Software fast schon von selbst die automatisierte Erkenntnis, wie Dinge ineinander greifen. Schließlich lässt sich durch die Kombination von RDF und OWL-Ergänzungen (sog. Annotationen ) auch eine automatisierte Deutung komplexer Textinhalte ermöglichen.
Ontologie

Zusammenhänge, Assoziationen etc.: Die Ontologie ist eine komplexe Mindmap: Was hängt wie zusammen? Für ihre Dokumentation gibt es den XML-Standard „OWL“.
Die Stärke dieser beiden für das Semantische Web optimierten XML-Standards liegt in ihrer hohen Verbreitung, Bekanntheit und Akzeptanz. Zudem gibt es schon eine Reihe von einfach zu bedienenden Editoren wie Altova .
Die Schwäche liegt hingegen darin, dass für jeden Begriff wie beispielsweise „Auto“ im Idealfall nur eine einzige allgemeinverbindliche Ontologie existieren dürfte – das hieße allerdings, die natürliche Vielfalt der Sprache einzuengen. An den Annotationen ist zudem eine kollaborative Arbeit erforderlich – ähnlich wie bei Web 2.0. Anders als bei Web 2.0 ist es jedoch nicht der Spaß, sondern eine andere Motivlage der Treiber, wie dies Studien im Rahmen des Ontoverse-Projekts belegt haben (sehr lesenswert dazu der Innowise Trendreport ). Eine Art „Weltwissen“ auf Basis von RDF- und OWL-Formaten zu schaffen ist sicherlich langfristig erstrebenswert. Doch überall dort, wo diese Standards (noch) nicht verwendet werden, muss auf andere Möglichkeiten der Sinn-Analyse zurück gegriffen werden.
Die ideale semantische Software muss also in der Lage sein, Texte selbstständig mit und ohne RDF- und OWL-Inhalte zu versehen, also automatisch zu annotieren. Sie muss dazu wenigstens zum Teil mit einem eigenem Welt- und Fachwissen arbeiten.
Annäherung verschiedener Lösungsverfahren
Als Zwischenfazit ist festzustellen: Die erfolgreiche Inhalts-Interpretation ist vor diesem Hintergrund wenigstens auf zwei Wegen möglich. Zwei Wege, die alternativ, aber auch kumulativ verwendet werden können:
- Die natürliche Sprache kann sich beim Erstellen von Inhalten der künstlichen Sprache anpassen ( = a priori Einengung der Deutungs-Vielfalt z.B. durch manuelle Zufügung von Metadaten, vgl. RDF und OWL-Beschreibungen)
- Die künstliche Sprache kann ihr Verständnis Richtung nicht linearer Abläufe erweitern und mit einem Weltwissen selbständig annotieren (= Integration von einer unscharfen „Fuzzy-Logik“ z.B. durch Training auf Basis probalistischer Systeme und/oder durch Verwendung neuronaler Netze )
Der zuvor skizzierte Weg der Verwendung von Standards wie RDF und OWL entspricht demnach vor allem dem ersten Ansatz: Es geht um die Einengung von Interpretationsmöglichkeiten und den Bau von standardisierten „Interpretationsgleisen“ im Idealfall direkt durch den Autor. Die natürliche Sprache wird damit quasi gleich bei der Erstellung von Inhalten mit einer künstlichen (Meta-)Sprache angereichert und so weitergehend vorstrukturiert.
Umwandlungsprozess von natürlicher in künstliche Sprache
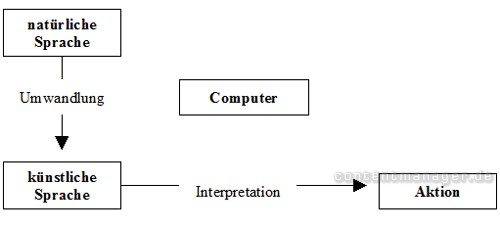
Dieser Prozess der manuellen Vorstrukturierung ist sehr aufwändig – und damit zeit- und kostenintensiv. Dort wo diese semantische Aufwertung nicht von Anfang an durch den Ersteller erfolgt, bleibt die Herausforderung des selbständigen Verstehens nach wie vor bestehen.
Es stellt sich daher die Frage: Wie kann unstrukturierte Information auch ohne vom Autor erstellte RDF und OWL-Ergänzungen in strukturierte Information umgewandelt und sinnvoll interpretiert werden? Anders gefragt: Wie funktioniert künstliche Intelligenz?
Automatische Annotation
Erste erfolgreiche Annäherungen an dieser Idee gibt es schon seit den 80er Jahren: Texte müssten sich doch inhaltlich so erschließen lassen, wie dies beim menschlichen Lesen der Fall ist – durch Assoziation. Innovative Ideen für entsprechende semantische Software-Lösungen kamen und kommen dabei häufig auch aus der Medizin bzw. der Biologie. Dies gilt insbesondere für künstliche neuronale Netze, die die Funktion des Gehirns nachahmen.
Ihre Überlegung ist einfach: Jedes Kind muss Sprache lang und aufwändig lernen, also üben, üben, üben. Erst über mehrere Jahre hinweg bildet sich ein umfassendes Sprachverständnis – durch regelmäßiges, aber vor allem empirisches Trainieren von Regeln. Durch dieses Verfahren werden beim Menschen im Gehirn neuronale Verknüpfungen gebildet. Ähnlich ist der Ansatz in der Neuro-Informatik. Dinge, die zusammen gehören, werden miteinander verknüpft – oder eben nicht:
- Ast gehört zu Baum, deshalb wird eine Verbindung erstellt
- Reifen gehört zu Auto, deshalb wird eine Verbindung erstellt
- Ast gehört nicht zu Auto und Reifen nicht zu Baum, daher keine Verbindung
Prüfung von Sinn-Möglichkeiten
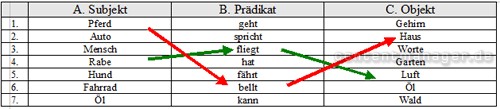
Was mach Sinn, was nicht? Die Kombination A4 / B3 / C5 macht Sinn, denn ein Rabe kann durch die Luft fliegen. Die Kombination A6 / B1 / A1 nicht, da ein Fahrrad nicht geht – egal wo! Und ein Pferd bellt nicht – schon gar nicht im Haus. Ebenso wenig hat Öl ein Gehirn – und Hunde sprechen nicht! Neuronale Netze ermöglichen die Analyse von derartigen semantischen Zusammenhängen, die durch Vektoren-Verknüpfung entstehen bzw. nicht entstehen. Anhand des Welt- und Fachwissens eines neuronalen Systems können so komplexe Verständnisaussagen getroffen werden.
Neuronale semantische Software sucht nach entsprechenden Verbindungen und nach deren Ausprägung (häufig oder selten), also der Relevanz der Assoziation. Entsprechende Ergebnisse werden dabei in mehrstufigen Taxonomie -Hierarchien zusammengefasst. Damit wird die Assoziationstiefe interpretierbar und damit eine Deutung von Inhalt und Zusammenhängen in Texten möglich.
Automatische Taxonomie-Erstellung
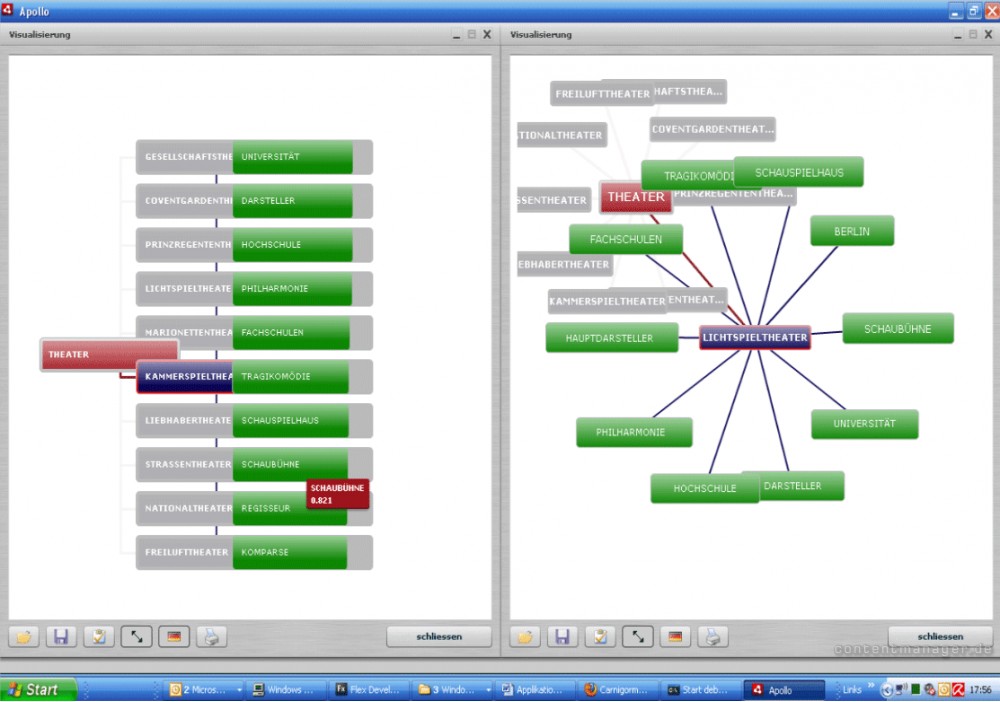
Eine automatisch erstellter Taxonomie-Baum macht sichtbar, welche Verknüpfungen in einem neuronalen Netz bestehen. Die Gewichtung der Assoziation ist dabei in diesem Fall auf der rechten Seite durch die Nähe zum Hauptbegriff erkennbar. Auf der linken Seite wird dies durch die Breite der grünen Balken verdeutlicht. Taxonomien dieser Art können händisch, aber auch automatisch erstellt werden.
Wie genau eine automatische Taxonomie entsteht, dieses Geheimnis schützen die Hersteller semantischer Software genauso intensiv wie Coca Cola die Rezeptur des gleichnamigen Getränks. Aber sicher ist: Eine solche Software kommt ihrerseits nicht ohne ein Weltwissen aus – das allerdings nicht mit RDF oder OWL-Standards aufbereitet sein muss, sondern auf Basis neuronaler Verknüpfung und damit eigenen Standards Sinninhalte speichert bzw. kodifiziert.
Der Hauptvorteil neuronaler Systeme ist dabei die Erfassung „unscharfer“ zum Teil auch mehrstufiger Zusammenhänge und die Bewältigung mehrdeutiger Aussagen. Zudem kann durch Trainieren der Grad der Assoziation den Nutzergewohnheiten angepasst werden. Insofern handelt es sich tatsächlich um selbstlernende Systeme. Die Tatsache, dass eigene Standards verwendet werden, macht das System zudem flexibler im Hinblick auf die Anpassung an individuelle Aufgabenstellungen.
Über die Vor- und Nachteile neuronaler Netze ist viel diskutiert worden: Insbesondere besteht das Problem, dass es sich bei dieser Technik letztlich um eine Art „Black-Box“ handelt, deren Ergebnisse nicht immer nachvollziehbar und ebenso wenig vorhersehbar sind. Diese Kritik ist im Grunde berechtigt, aber auch nur insoweit korrekt soweit eine Software ausschließlich auf neuronalen Verknüpfungen basiert. Gemischte Systeme, die mit einer Kombination von probabilistischen und neuronalen Methoden arbeiten, sind diesbezüglich deutlich stärker als die reinen neuronalen Systeme.
Zwischen-Fazit
Um auf die Eingangsbeispiele zurück zu kommen:
Semantische Software ist grundsätzlich in der Lage, Inhalte zu interpretieren. Sie ist in diesem Sinne heute schon wesentlich realer als ein „sprechender Hund“ jemals real sein wird. Darüber hinaus besitzt semantische Software – anders als Öl – die Fähigkeit, das menschliche Gehirn zumindest in Grundzügen nachzuahmen. In diesem Fall ist es also keine freche Behauptung, sondern eine zukunftsträchtige Technologie, deren Entwicklung gerade erst richtig begonnen hat.
Es lohnt sich daher schon heute, semantischer Technologie konkrete und anspruchsvolle Aufgaben zu stellen! Die Aktionsziele können dabei recht unterschiedlich sein. Wichtige Fälle sind:
- Eindeutige Klassifikation von Informationen (z.B. Clustering von Dokumenten)
- Verwandschaftsgrad von Informationsinhalten prüfen (z.B. Taxonomie)
- Retrieval von Informationen (z.B. Suchmaschine)
- Entscheidungsunterstützung (z.B. Management-Software)
- Matching-Analysen (z.B. Partnersuche oder Jobsuche)
- Unbekannte Zusammenhänge erkennen (z.B. Innovationssuche)
Semantische Software muss zur Lösung dieser Aufgaben die Zielsetzung kennen, aber auch den der Zielsetzung umgebenden Kontext erfassen. Nur durch die Berücksichtigung der Rahmenfaktoren kann eine Deutung des Inhalts korrekt erfolgen. Die Qualität der Resultate ist deshalb sowohl von der Software, aber auch dem Kontext der Aufgabenstellung abhängig: In dieser Hinsicht muss die Software also exakt „kalibriert“ werden können.
Ziel und Kontext der Kommunikation
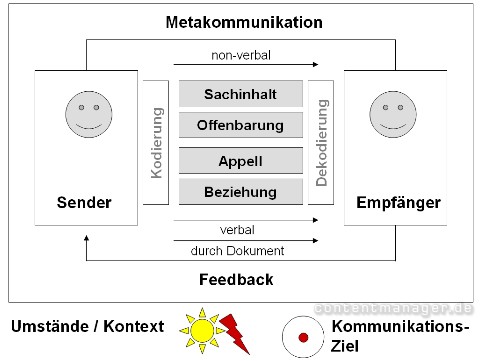
Menschliche Kommunikation ist extrem vielschichtig, mitunter nonverbal und daher häufig nur durch den Kontext und die Intension der Kommunizierenden verständlich. Sender und Empfänger sind diese Umstände in der Regel zumindest im Unterbewusstsein bekannt. Für semantische Software ist es nach wie vor wichtig, diese Parameter im Vorfeld einer zu bewältigenden Aufgabe zu definieren. Eine Kalibrierung ist deshalb erforderlich: Dabei handelt es sich quasi um Stellschrauben zur Justierung semantischer Interpretaion: Was ist zu beachten? Was muss unbeachtet bleiben? Welche Aktion wird am Ende unter welchen Voraussetzungen erwartet?
Im nächsten Teil wird u.a. anhand der Beispiele „Social-Media-Monitoring“, „Enterprise-Search“ und „Beschwerdemanagement“ dargestellt, wie sich der Kontext auf die Erschließung des Inhalts auswirkt.
Bildquellen




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
No Comment